Welcome to Jaehyek's Blog!
Here is my front-end learning path-
Six Sigma Terminology
Six Sigma 용어 정리
- 범주형 ( Categorical or Attribute )
- 이산형 ( Discrete )
-
연속형 ( Continuios )
- Descriptive Statistic : 기술 통계
-
Inferential Statistic : 추리 통계
- Population : 모집단
-
Parameter : 모수
- Sample : 표본
-
Statistic : 통계량
- Type I error : 1종오류
-
Type II error : 2종오류
- hypothesis : 가설
-
hypothesis testing : 가설검정
-
power of test : 검정력 가설검정에서 영가설이 사실이 아닐 때 이를 기각하여 올바른 결정을 할 수 있는 확률
- coefficient of determination : 결정계수
-
eigenvalue : 고유값 자료행렬을 요약하는 낱개의 수치. 특성치라고도 함. 각 고유값에는 그에 대응하는 고유벡터가 있고 하나의 행렬은 고유치와 고유벡터에 의해 분해될 수 있다. 고유값의 부호는 +, -, 또는 0이 되는데 사회과학에서는 +의 고유값을 자료내 정보의 양으로 해석하는 경우가 있다(예: 요인분석에서)
-
analysis of Covariance: ANCOVA : 공분산분석 일반선형모형에 기초한 통계적 기술로서 회귀분석과 분산분석 방법이 결합된 통계적 방법
-
cluster analysis : 군집분석 관찰대상인 개체들을 유사성에 근거하여 보다 유사한 동류집단으로 분류하는 다변량분석기법.
-
outlier : 극단치 통계적 자료분석의 결과를 왜곡시키거나, 자료분석의 적절성을 위협하는 변수 값 또는 사례
-
content validity : 내용타당도
-
MANOVA : multivariate analysis of variance : 다변량분산분석
-
homoscedasticity : 등분산성 어떤 통계모형에서 정의된 잔차(오차)항의 분산이 독립변수나 예측변수의 각 관찰값에서 동일한 값을 보이는 성질
- percentile rank : 백분위
-
centile/percentile/percentile score : 백분위수
- Bayesian statistics : 베이즈통계학
-
variance : 분산 한 분포를 구성하는 모든 사례에서 그 분포의 평균을 빼서 나온 편차점수들을 제곱하고, 이를 모두 합한 후 그 분포의 사례수로 나눈 값 표준편차의 제곱값
-
ANOVA : analysis of variance : 분산분석 집단간 분산과 집단내 분산의 비율인 F통계량(F = 집단간 분산/집단내 분산)이다.
-
distribution : 분포
-
unbiased estimation : 불편파추정 즉 추정량의 기대값이 추정할 모수의 실제값과 일치하거나 또는 그 값에 가까울수록 바람직한 추정량이라고 할 수 있다. 만약 추정량의 기대값이 실제 모수의 값과 차이가 나면, 그 추정량은 편파성(bias)을 갖는다고 한다
-
nonparametric statistical test : 비모수통계검정
- scatter plot : 산포도
-
correlation coefficient : 상관계수
-
linear regression analysis : 선형회귀분석 선형성이라는 기본 가정이 충족된 상태에서 독립변수와 종속변수의 관계를 설명하거나 예측하는 통계 방법. 독립변수가 하나인 경우를 단순회귀분석, 여러 개인 경우를 중다회귀분석이라고 한다
-
time-series analysis : 시계열분석 동일한 현상을 시간의 경과에 따라 일정한 간격을 두고 반복적으로 측정하여 각 기간에 일어난 변화에 대한 추세를 알아보는 방법
-
confidence interval : 신뢰구간 전집(population)의 평균은 표본의 평균을 바탕으로 추정되는데, 이때 전집의 평균을 포함하고 있으리라 확신하는 구간
-
reliability : 신뢰도
-
alpha level : 알파수준 : significance level (유의수준 ) 가설검정에서 영가설이 실제로 참임에도 불구하고 실수로 영가설을 기각할 확률인 제1종 오류의 수준
-
null hypothesis : 영가설 연구에서 검정을 받고자 하는 두 개의 대립되는 가설 중 직접 검정 대상이 되는 가설
-
alternative hypothesis : 대립가설
-
factor analysis : 요인분석 관찰된 변수들을 설명할 수 있는 몇 개의 요인으로 요약하는 방법
-
binomial distribution : 이항분포
-
normal distribution : 정규분포
-
dependent variable : 종속변수
-
principle component analysis : 주성분분석 주어진 확률벡터 X를 선형변환(linear transform)시켜서 X 보다 성분수가 더 적은 새로운 확률벡터 Y를 얻되, Y가 X에 대한 분포적 정보를 최대한 포함하여 Y를 구성하는 확률변수들 상호간의 상관계수가 0이 되게 하는 통계적 기법
-
main effect : 주효과 분산분석에서 독립변수 또는 실험요인의 효과
- multicollinearity/collinearity : 다중공선성 다중회귀분석에서 독립변수들간에 존재하는 상관관계
-
BOOK-가장 빨리 만나는 Deep Learning with Caffe
2.2 음성 인식(voice recognition) 분야의 성과
- Baidu Deep Speech은 Bi-directional Recurrent Neural Network
2.3 이미지 인식(image recognition) 분야의 성과
- 이미지넷은 이미지 인식 콘테스트 ILSVRC 을 매년 실시
- 이미지 set을 공개 http://image-net.org
ILSVRC2012 결과
Ranking Team Name Error Rate 1 supper vision 0.15315 2 supper vision 0.16422 3 ISI 0.26172 4 ISI 0.26602 5 ISI 0.26646 -
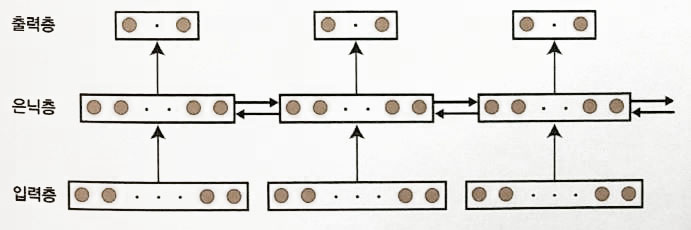
supper vision이 이용한 Neural Network
-
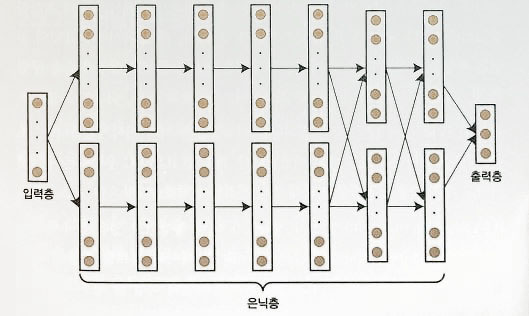
LeCunn 팀과 Supper vision과 비교
items LeCunn Suppe Vision Layers 8 layers 13 layers Image Size 32x32 224x224 output nodes 10 1000 total nodes 9118 831304 -
GoogleNet은 22 Layer을 이용해 ILSVRC2015에서 4.94% error rate 달성
-
LeCunn은 유튜브에서 이미지 1000만장을 추출 및 autoencoder을 이용하여 비지도 학습을 하고, 고양이나 사람에 반응하는 부분이 만들이 진 것을 발견.
-
페이스북 연구자들은 딥러닝을 적용하여 얼굴 인증기법을 제안하여 97%에 달성.
- 우선 전처리로 이미지 안의 얼굴 부분에 얼굴 형상을 나타내는 3차원 폴리곤을 투영합니다.
- 폴리곤을 기본으로 위치와 방향을 정합하는 이미지 변환을 실행합니다.
- 변환된 이미지를 훈련 데이터로 사용하여 CNN 학습모델을 만들어 냅니다.
-
딥러닝을 이용한 노이즈 제거는 원래 이미지를 입력으로, 노이즈가 제거된 이미지를 출력으로 학습시킨다.
-
인페이팅 처리란 이미지속의 불필요한 부분을 제거하는 것으로, 원래 이미지를 입력으로, 인페이팅 처리후의 이미지를 출력으로 하여 학습한다.
-
초 해상도 처리란 저해상도를 입력으로, 고해상도 출력으로 학습시킨다. 초 해상도 기법으로 스파스 코딩(sparse coding) 이 알려져 있습니다.
-
딥 러닝을 이용해 이미지에 주석을 달기 : 구글 비냘스(Vinyals)팀
3.2 이미지 인식 분야의 성과
기존의 이미지 인식 기법
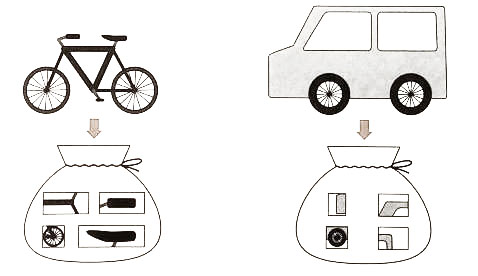
- 이미지 특징점: 나란히 연결된 픽셀과 픽셀 사이의 휘도값이 크게 차이가 난 부분.
- 알려진 기법 : SIFT, SURF, ORB, CARD, AKAZE
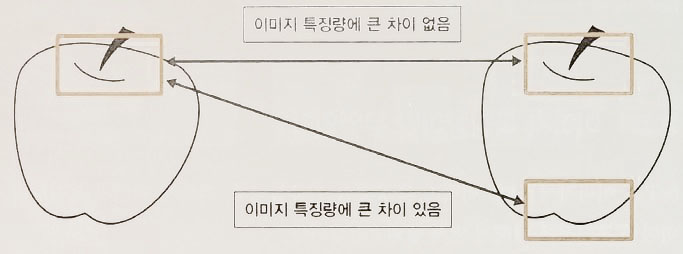
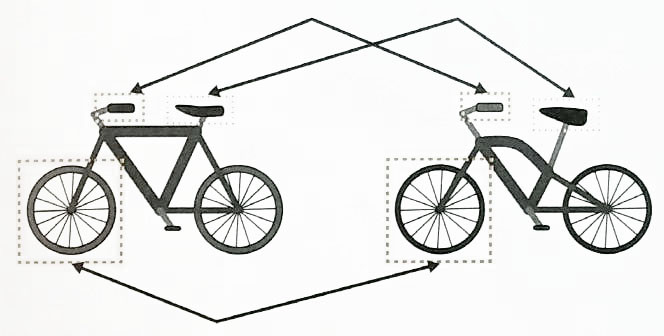
BoF 의 개념
- Bag of Features : 같은 종류의 물체는 비슷한 Feature 가 많다는 가정에서 출발.
- 비슷한 feature가 많으면 같은 종류다.
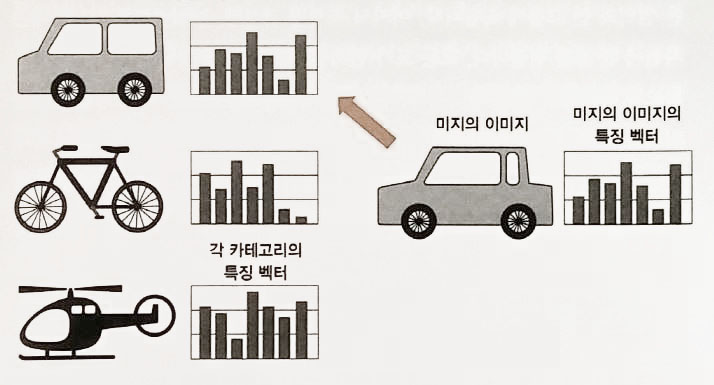
- BOF을 이용한 이미지 인식은 이미지를 일정한 벡터형식으로 나타냅니다.
- 이 벡터를 특징벡터라고 하고, 이미지가 어떤 배치(bag, feature)를 갖고 있는지 나타낸다.
- 이미지 특징점들은 위치 관계는 전혀 고려하지 않는다.
- 이미지는 보는 각도에 따라 영향을 받는다.
4 딥러닝 알고리즘 학습 방법 ( Deep Learning Algorithm Mathod )
입력층 활성화 함수 ( Input layer activation function )
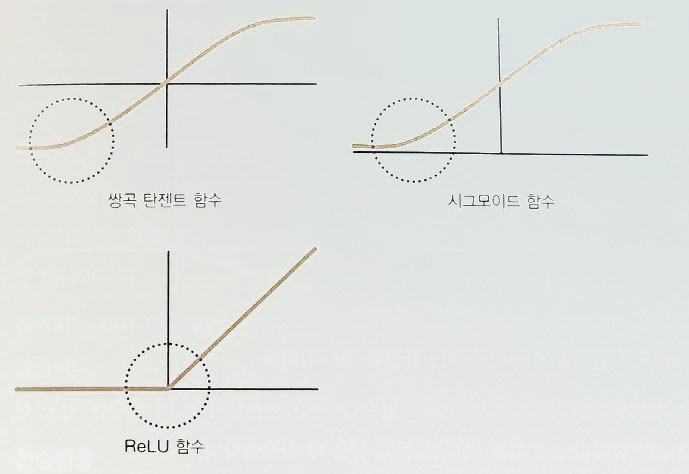

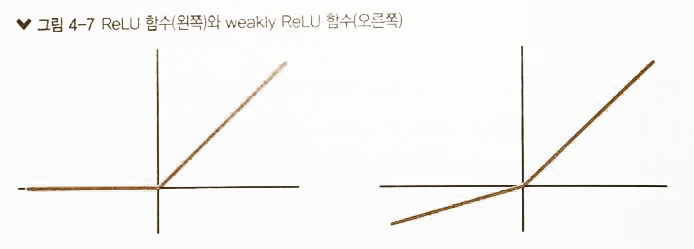
출력층 활성화 함수 ( Output layer activation function )
- softmax을 자주 사용합니다.
계층의 종류 ( Layer class )
- 전결합층
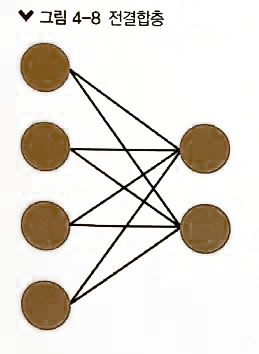
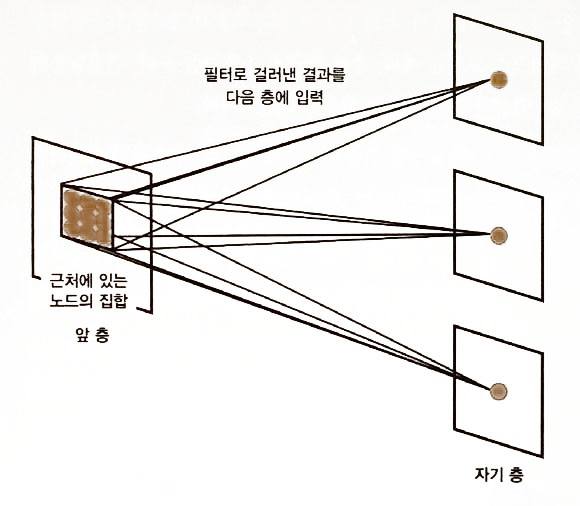
- 컨볼루션층 (convolution layer): 이미지에서 특징을 추출
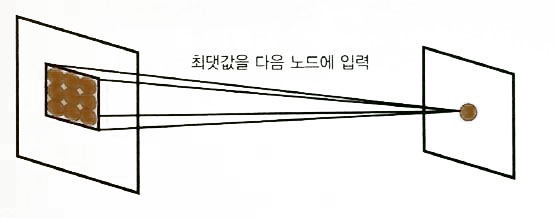
- 풀링층(pooling layer) : 국소적인 노드의 최대값을 취합 : 범위내 작은 변화는 같은 결과 값으로 표현.
Gradient Method

신경망을 정밀하게 학습
- Dropout : 2012년 Hinton교수가 제안.
- 임의의 노드 몇개를 생략하고 계산함. 또 다음 계산때에도 임의의 노드를 생략하고 계산.
- 입력층에는 20%, 은닉층에서는 50%
- 앙상블 학습과 비슷
- Drop connect : 연결가중치를 램덤하게 생략.
- Adaptive Dropout : 연결상황에 따라.
- AdaGrad
- AdaDelta
- Adam
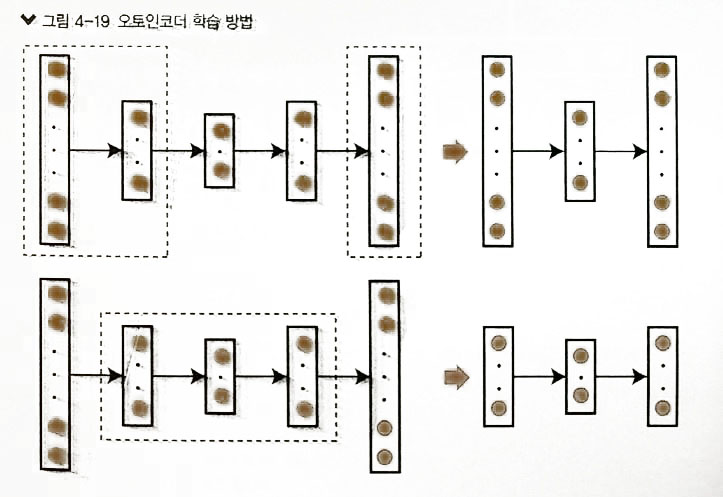
오토인코더( Autoencoder )의 학습 방법
- 입력층과 출력증의 값이 같은 Neural Network
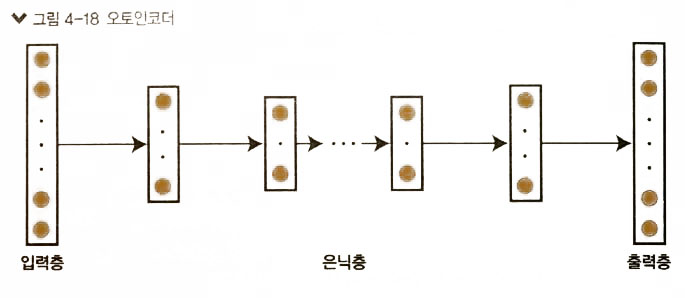
- 학습방법
- 입력층,1st 은닉층, 출력층으로 먼저 학습. –> 가중치 계산
- 1st 은닉층, 2nd 은닉층, 3th 은닉층 –> 학습
4 Caffe을 준비하다.
-
Caffe란 : 버클리대학교 BVLC(Berkerly Vision and Learning Centor )에서 개발한 Framework
-
Open Source Framework
-
HTML Tag CSS PPT 정리
Inflearn에서의 “실전 HTML & CSS 강좌” 입니다.
강의는 HTML 기본-I편입니다.
- 태그란
- HTML버전과 편집툴
- HTML태그 개요
- h1,p,br,a,b,i,sup,ins,del 태그
ppt doc
이번 강의는 HTML 기본-II편입니다.
- 리스트 태그 – ul,li,ol
- 표를 나타내는 태그 – table
- 이미지를 출력하는 태그 – img
- 사운드를 출력하는 태그 – audio
- 주간 히트송 예제
ppt doc
이번 강의는 HTML 기본-III편입니다.
- 동영상을 출력하는 태그 – video
- 폼 태그
- 레이아웃 구성 태그 – div, span
ppt doc
이번 강의는 HTML기본-IV 편입니다.
- div를 이용한 레이아웃
- 시멘틱을 이용한 레이아웃
ppt doc
CSS 기본 I
- 선택자란?
- tag 선택자
-
- 선택자
- 전체와 특정태그의 혼합
ppt doc
CSS 기본 – 2편입니다.
- tag,id, class 혼합
- 속성 선택자
- 후손 및 자손 선택자
- 동위 선택자
ppt doc
이번 강의는 CSS 기본-III편입니다.
- 반응 선택자
- 상태 선택자
- 구조 선택자
- 전체적인 레이아웃 설정
ppt doc
이번 강의는 CSS 기본-IV편입니다.
- 문자 선택자
- 링크 선택자
- 부정 선택자
ppt doc
강의 내용 속성 1편
- CSS3 단위
- url()
- display 속성
- visibility 속성
- opacity 속성
ppt doc
강의 내용 속성 2편
- margin 및 padding 속성
- box-sizing 속성
- border 속성
- background-image 속성
ppt doc
강의 내용 속성 3편
- font-family , font-size 속성
- font-style, font-weight, line-height 속성
- text-align, text-decoration 속성
- position 속성
ppt doc
강의 내용 속성 4편
- float 속성
- gradient 속성
ppt doc
-
Game Theory @ Standford University
게시일: 2013. 8. 5. [비디오 정보] 2013년 4월 27일 스탠포드에서 게임 이론에 관한 공개 강연을 녹화한 것입니다. 강연이 Part 1과 Part 2로 나뉘어져 있으며, 이 비디오는 Part 1 입니다. 강연의 주최 기관은 SEED Stanford 입니다 ( 페이스북 페이지 참고: https://www.facebook.com/SEED.Talk/. ).
[강연 소개] 게임 이론 (Game Theory)은 독립된 학문으로 인식된지 100년이 채 되지 않은, 비교적 역사가 짧은 과학의 한 분야임에도 불구하고 적용 분야가 많아 economics, computer science, biology, philosophy, 그리고 political science에서 공통적으로 연구되는 학문입니다. 일상 생활에서도 경매, 투표, 포커 게임의 전략, 검색 엔진의 “sponsored results” 등에 이르기 까지 게임 이론은 알게 모르게 우리 생활에 영향을 주고 있습니다. 이번 모임에서는 게임 이론에 대한 소개, 그리고 일상 생활에 게임 이론이 적용된 사례가 어떤 것들이 있는지를 알기 쉽게 설명하고 함께 이해하는 시간을 가지려 합니다. 게임 이론에 대한 배경 지식이 전혀 없더라도 이해할 수 있도록 준비하였으니 많은 분들의 참석 바랍니다.
[연사 소개] 이후연: Computer Science 박사과정 2년차 (Stanford University)
[References]
[1] 슬라이드에 등장하는 포스터 이미지 (4컷)는 아래 웹 페이지에서 영감을 얻어 자체 제작했습니다. 부제도 퍼왔습니다. http://embracingtheblackrage.blogspot.kr/2012/11/game-theory-101.html
[2] Prisoner’s dilemma (이미지)는 아래 그림에서 영감을 얻어 자체 제작했습니다. <https://deathbytrolley.files.wordpress.com/2013/01/prisoners_dilemma_23.gif)
[3] Guessing game results, excerpted from: TED talk Colin Camerer의 TED talk에 사용되었던 guessing game관련 자료를 사용했습니다. 토크 내용은 아래 주소에서 확인 가능합니다. http://www.ted.com/talks/colin_camerer_neuroscience_game_theory_monkeys
[4] Southwest Airlines 예제: 아래 블로그에 자세한 내용이 있습니다. http://mindyourdecisions.com/blog/category/game-theory/
[5] 영상 초반에 등장하는 Game Theory Textbook: “Multiagent Systems” 라는 책의 한 페이지를 보여주었습니다. 아래 웹사이트에서 책 정보 확인 가능합니다. http://www.masfoundations.org/
[100] 그 외의 예제들 - 사용된 예제들은 대부분 Game Theory에서 가장 잘 알려진 Classic example들 입니다.
[101] Part II 비디오 주소: http://youtu.be/ejTbWq37jk8
*누락된 reference가 있을시 수정/추가하겠습니다. 카테고리 교육 라이선스 표준 YouTube 라이선스
-
eMMC & UFS FTL (5)
FTL Features
Super-block and SLC/MLC mode
- Super-block is necessary to use multi-plane cmds for high r/w speed
- Super-block is a group of same block
- Size of super-block is 16MB=4X4M for 2 die, or 32M for 4 die
- Every allocation is based on a super-block
- The mode (SLC or MLC) is selected at the super-block allocation
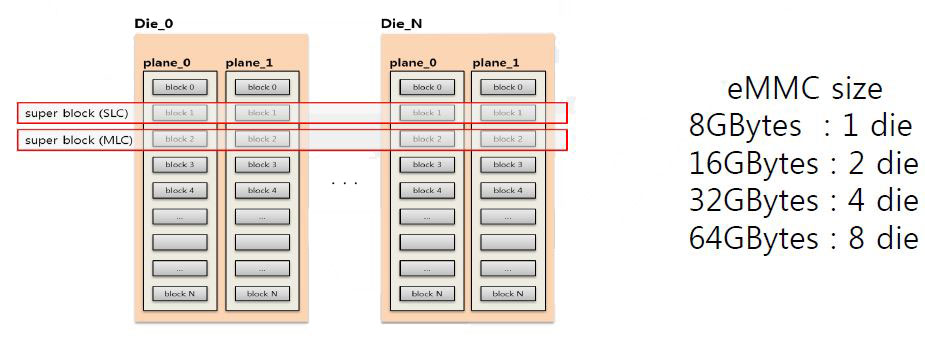
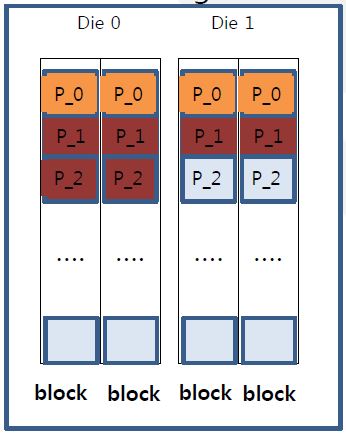
- Basic allocation unit of MLC log-buf is two pages
- MLC log-buf always uses multi-plane prog command for high speed
- Multi-plane program should use same page-number
- Write request sequence:
W_req_1 : 48KB=16KB x 3
W_req_2 : 70KB =16KB x 5
- W_req_1 : allocate 4 pages while skipping one page
- W_req_2 : allocate 6 pages while skipping one page
Log-buf Algorithm
- Based on write-req size, allocating user-data into SLC-log or MLC-log
- below 16K, go to SLC
- Over 16KB, go to MLC
- Basically, two logs for one SLC log and one MLC log
- However, four log is possible for two SLC logs and two MLC logs
- Actual consumed blocks is totally different with write patterns
pattern Traffic amount (Bytes) Consumed SB WA 128 times of 4K 512K 0.25 8 128 times of 16K 2M 0.25 2 256 times of 20K 5120K 0.5 1.6 256 times of 32K 8192K 0.5 1 SB life-cycle
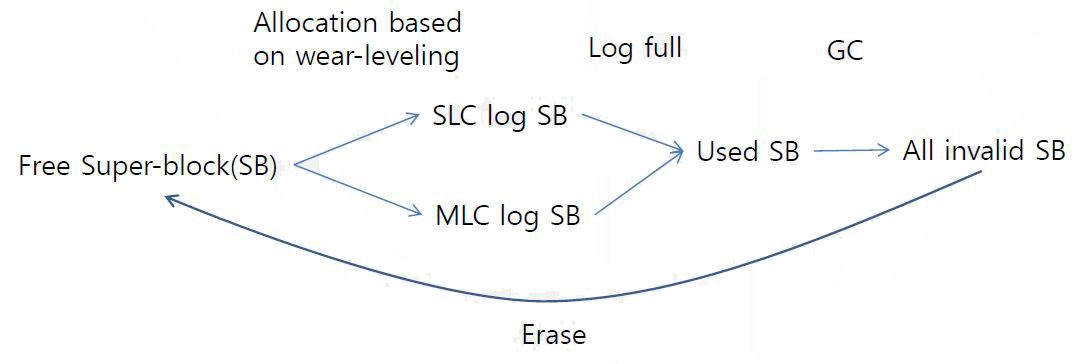
Allocation algorithm
- Write sequence
- Logical address (1, 2, 3, 4, 5, 6, 7, 4, 8, 9, 10, 4, 11, 12, 13, 4, 14, 15, 16, 4)

- GC Cost
- 12 page copies and one erase V.S. one erase
- In case of 256 pages, Write amplification 255 V.S. 1
- Hot/cold Awareness is important
Paired page issue
- a page programmed successfully can be broken if the following paired page is damaged by power-failure
- Damage of Pm+1 crashes P2’s content which is programmed successfully
- =>Solution : backup P2 before Pm+1
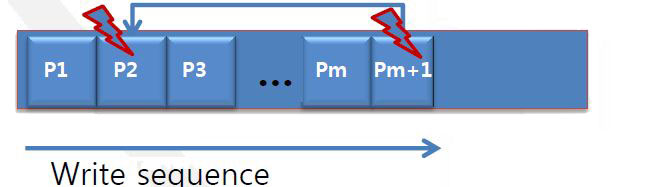
- Solution
- before starting programming Pm+1, the paired page, P2, is copied to temporal buffer
- The temp buffer should be scanned at booting to recovery P2’s content if that is crashed
- Write request for Pm+1 arrives
- Copy the paired page into temporal SLC block
- Program Pm+1
Simple full page map
- Every Logical block(LB) has an physical page address(PPA)
Element Size (Bytes) Comments Nand page 16KB Logical block 16KB Total number of map element 2048KB 32GB /16KB Size of map 8192KB 4Bytes X 2048K Total number of pages for map 512 ea 8192KB/16KB Map-table structure
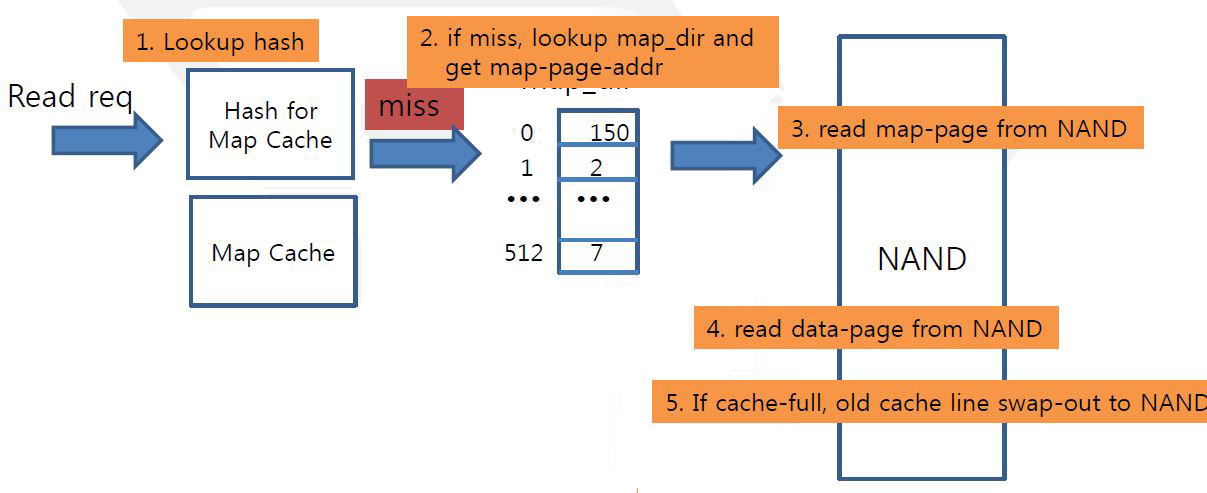
- Map_dir
- Map_page 1)Write request for 4096 LB arrives 2)Lookup map_dir & get ppa 2 for map_page 3)Lookup map_page & get ppa 12144 for data
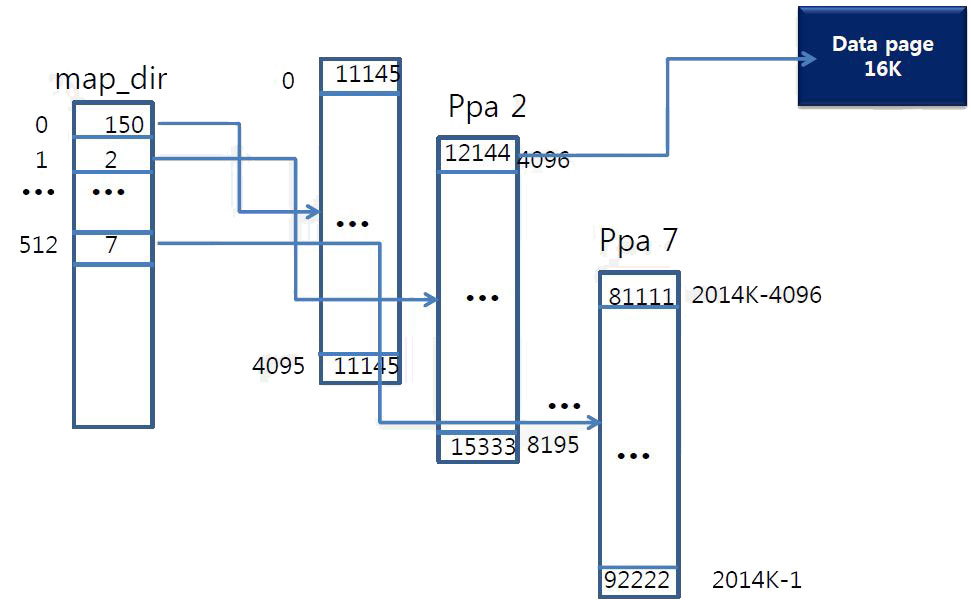
NAND Area Partition
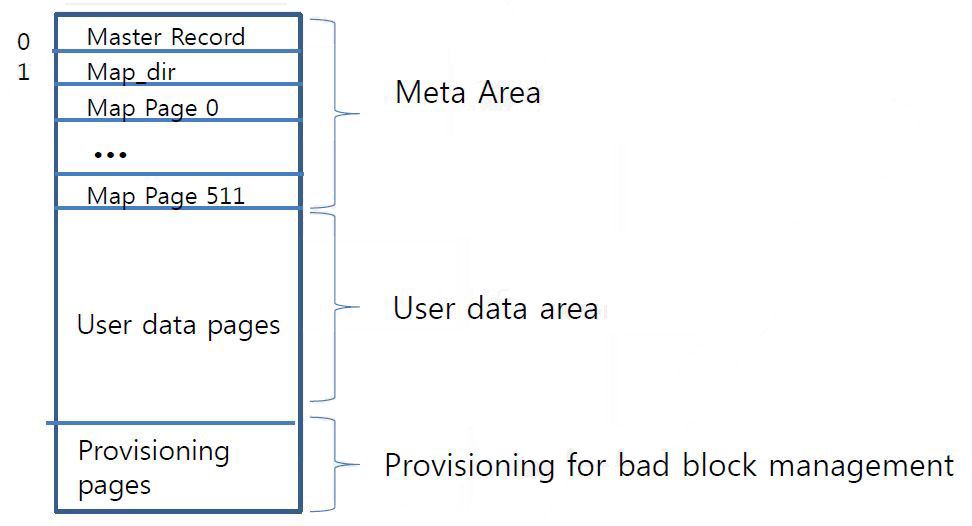
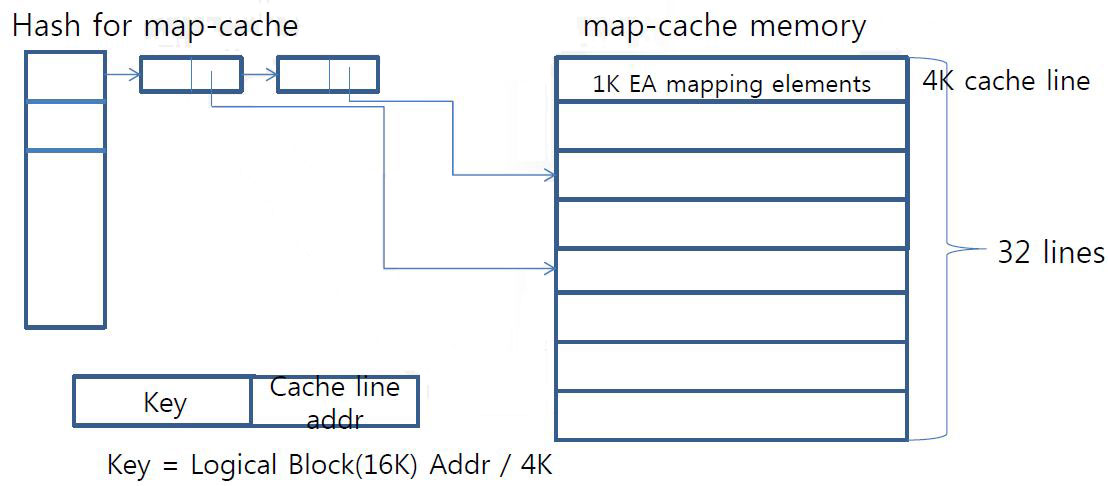
Map cache
- SRAM of eMMC is too small for all map
- SRAM is around 256K and consumed for (code, data buffer, map)
- SRAM for map is under 128K
- Map-cache is SRAM area to keep small part of the entire map-table
Read Sequence
Worst cases : frequent map-update
- Cache-line is 4K bytes which contains 1K ea mapping info
- covering 16M logical area (1K X 16K page)
- Writes sequences
- Page 0, page 1K, page 2K, … , page
- Update map-page into NAND per writing every pages
- Programming 2 NAND pages for each 1 page write request

-
eMMC & UFS FTL (4)
MEMCON and ONFI (Open NAND Flash Interface) http://www.ofni.org
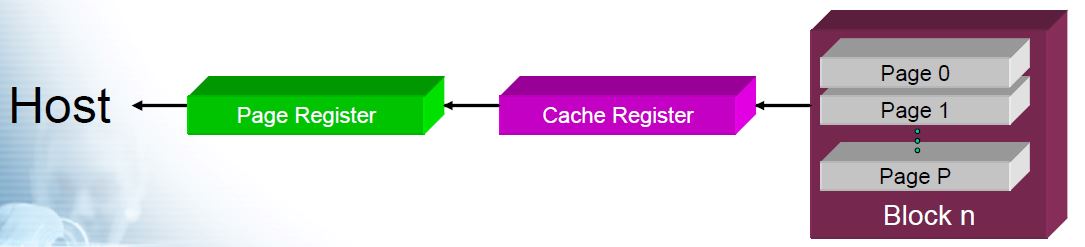
Removing the Page Register Bottleneck
- While the host is reading data from the page register, the next page could be read from the array
- But… there is only one page register…
- The NAND vendors added a cache register to solve this issue
Multiple Plane Operations
- NAND vendors have started splitting the array into “planes” within a die
- Allows simultaneous operations of the same type to different block addresses
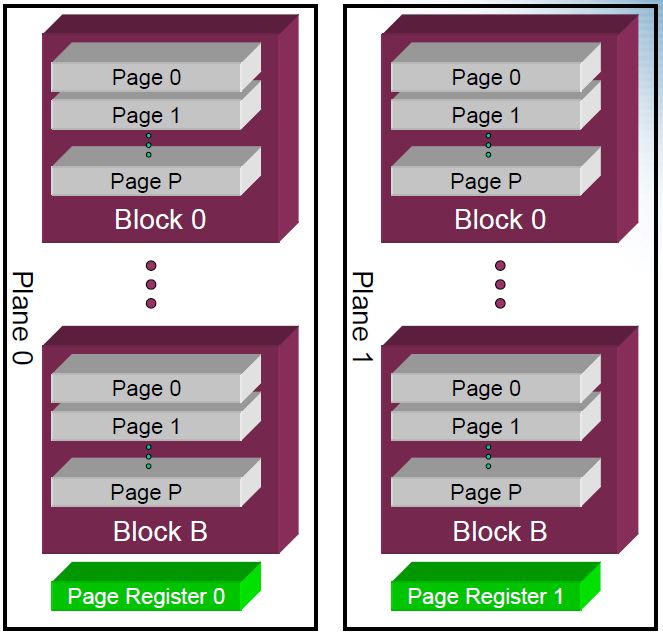
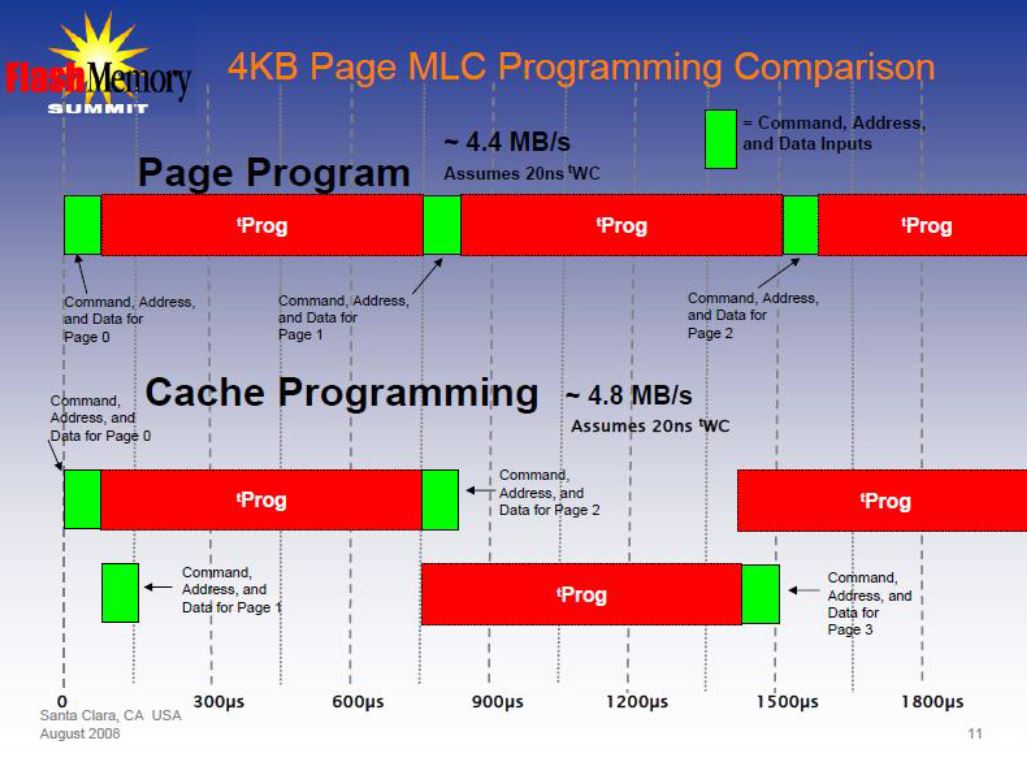
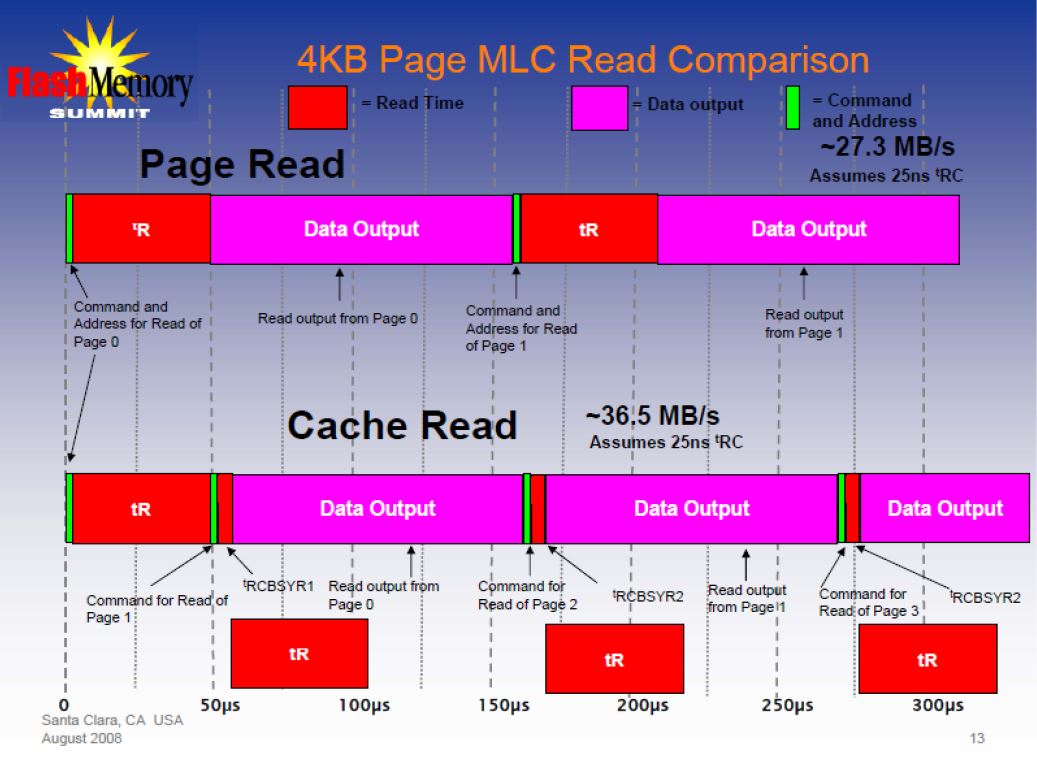
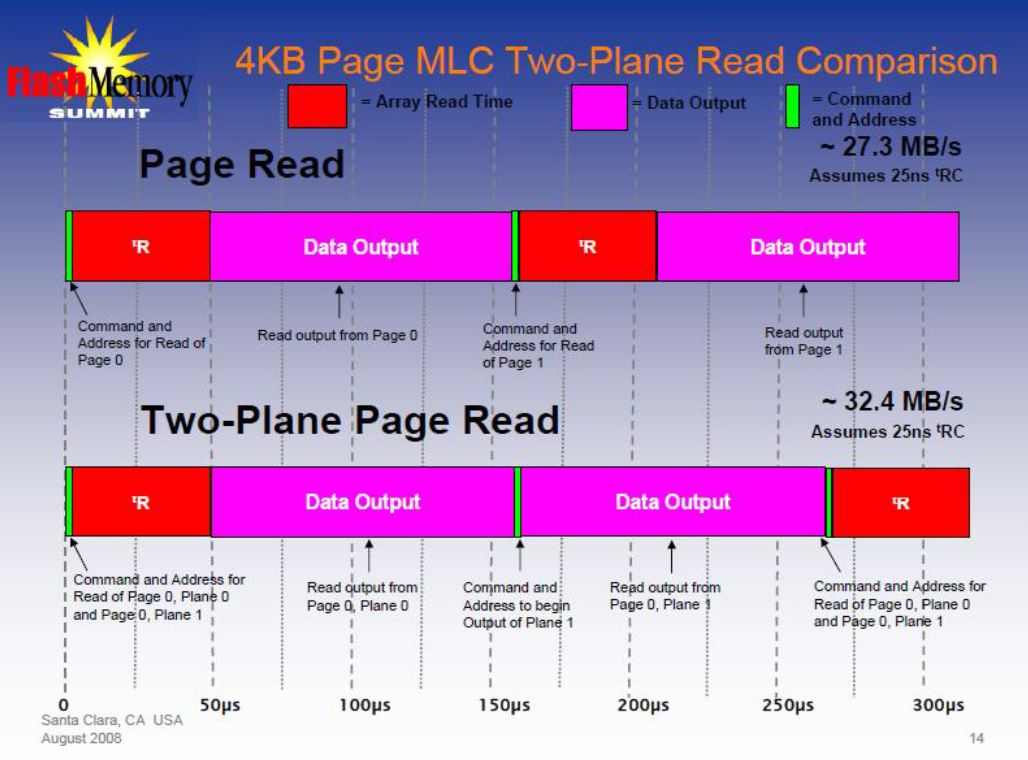

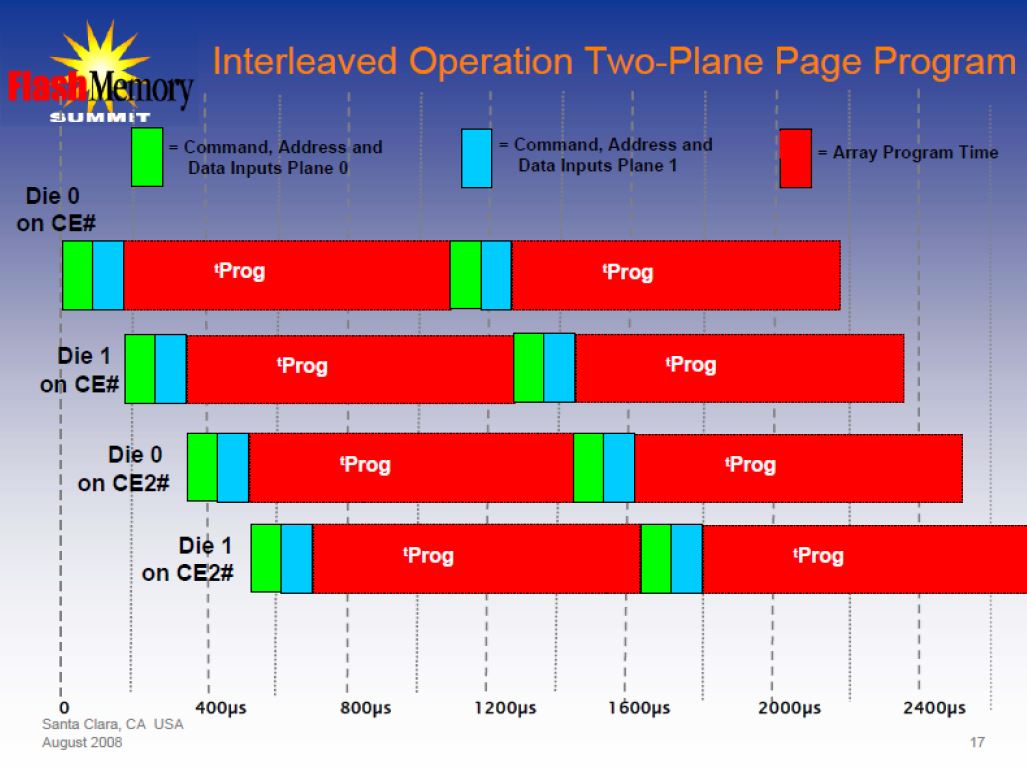
Multiple Plane Read Operations
- Multiple plane read operations are when multiple reads are issued at roughly the same time
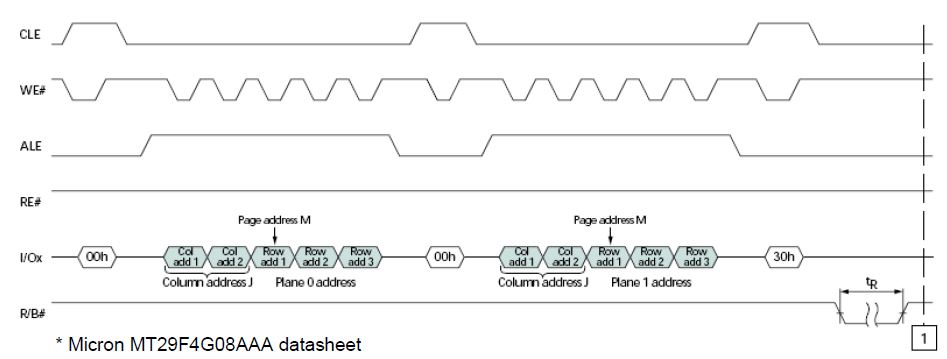
- Limitation: Page address for reads have to be the same
- Install Tensorflow and OpenCV on Raspberry PI 3
- Install Tensorflow on Windows
- Tensorflow 0.x => 1.0 Migration Guide
- eMMC UFS Issues 17
- Deep Learning summary from http://hunkim.github.io/ml/ (4)
- Deep Learning summary from http://hunkim.github.io/ml/ (3)
- Deep Learning summary from http://hunkim.github.io/ml/ (2)
- Deep Learning summary from http://hunkim.github.io/ml/ (1)
- Summary of CNN base cs231n.github.io
- BOOK-TCP/IP 쉽게 더 쉽게-03