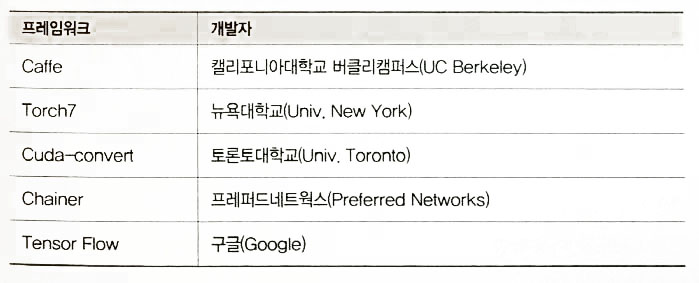
2.2 음성 인식(voice recognition) 분야의 성과
- Baidu Deep Speech은 Bi-directional Recurrent Neural Network
2.3 이미지 인식(image recognition) 분야의 성과
- 이미지넷은 이미지 인식 콘테스트 ILSVRC 을 매년 실시
- 이미지 set을 공개 http://image-net.org
ILSVRC2012 결과
| Ranking | Team Name | Error Rate |
|---|---|---|
| 1 | supper vision | 0.15315 |
| 2 | supper vision | 0.16422 |
| 3 | ISI | 0.26172 |
| 4 | ISI | 0.26602 |
| 5 | ISI | 0.26646 |
-
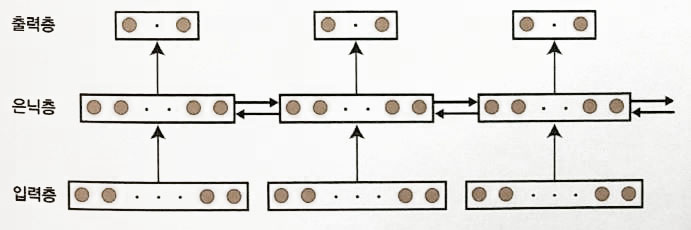
supper vision이 이용한 Neural Network
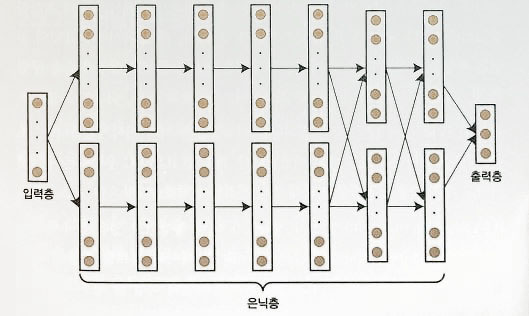
-
LeCunn 팀과 Supper vision과 비교
| items | LeCunn | Suppe Vision |
|---|---|---|
| Layers | 8 layers | 13 layers |
| Image Size | 32x32 | 224x224 |
| output nodes | 10 | 1000 |
| total nodes | 9118 | 831304 |
-
GoogleNet은 22 Layer을 이용해 ILSVRC2015에서 4.94% error rate 달성
-
LeCunn은 유튜브에서 이미지 1000만장을 추출 및 autoencoder을 이용하여 비지도 학습을 하고, 고양이나 사람에 반응하는 부분이 만들이 진 것을 발견.
-
페이스북 연구자들은 딥러닝을 적용하여 얼굴 인증기법을 제안하여 97%에 달성.
- 우선 전처리로 이미지 안의 얼굴 부분에 얼굴 형상을 나타내는 3차원 폴리곤을 투영합니다.
- 폴리곤을 기본으로 위치와 방향을 정합하는 이미지 변환을 실행합니다.
- 변환된 이미지를 훈련 데이터로 사용하여 CNN 학습모델을 만들어 냅니다.
-
딥러닝을 이용한 노이즈 제거는 원래 이미지를 입력으로, 노이즈가 제거된 이미지를 출력으로 학습시킨다.
-
인페이팅 처리란 이미지속의 불필요한 부분을 제거하는 것으로, 원래 이미지를 입력으로, 인페이팅 처리후의 이미지를 출력으로 하여 학습한다.
-
초 해상도 처리란 저해상도를 입력으로, 고해상도 출력으로 학습시킨다. 초 해상도 기법으로 스파스 코딩(sparse coding) 이 알려져 있습니다.
-
딥 러닝을 이용해 이미지에 주석을 달기 : 구글 비냘스(Vinyals)팀
3.2 이미지 인식 분야의 성과
기존의 이미지 인식 기법
- 이미지 특징점: 나란히 연결된 픽셀과 픽셀 사이의 휘도값이 크게 차이가 난 부분.
- 알려진 기법 : SIFT, SURF, ORB, CARD, AKAZE
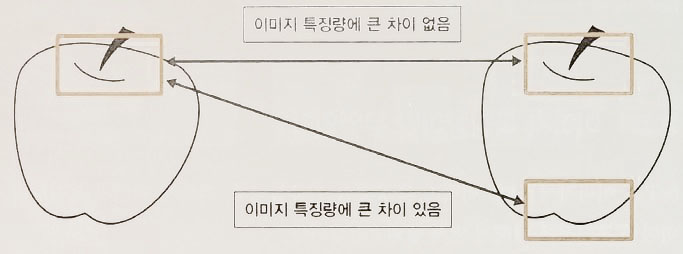
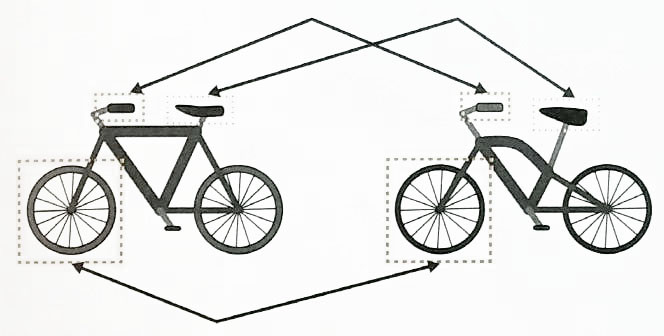
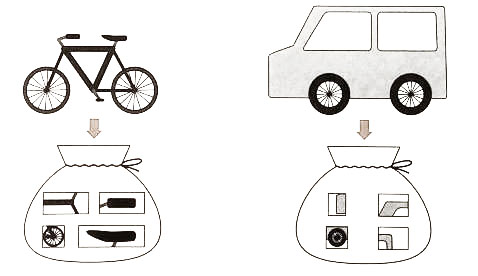
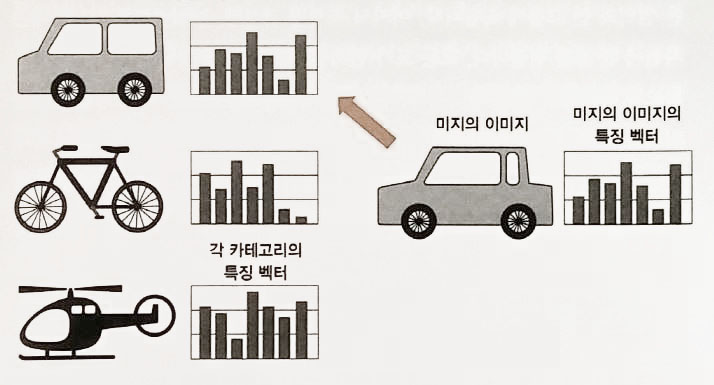
BoF 의 개념
- Bag of Features : 같은 종류의 물체는 비슷한 Feature 가 많다는 가정에서 출발.
- 비슷한 feature가 많으면 같은 종류다.
- BOF을 이용한 이미지 인식은 이미지를 일정한 벡터형식으로 나타냅니다.
- 이 벡터를 특징벡터라고 하고, 이미지가 어떤 배치(bag, feature)를 갖고 있는지 나타낸다.
- 이미지 특징점들은 위치 관계는 전혀 고려하지 않는다.
- 이미지는 보는 각도에 따라 영향을 받는다.
4 딥러닝 알고리즘 학습 방법 ( Deep Learning Algorithm Mathod )
입력층 활성화 함수 ( Input layer activation function )
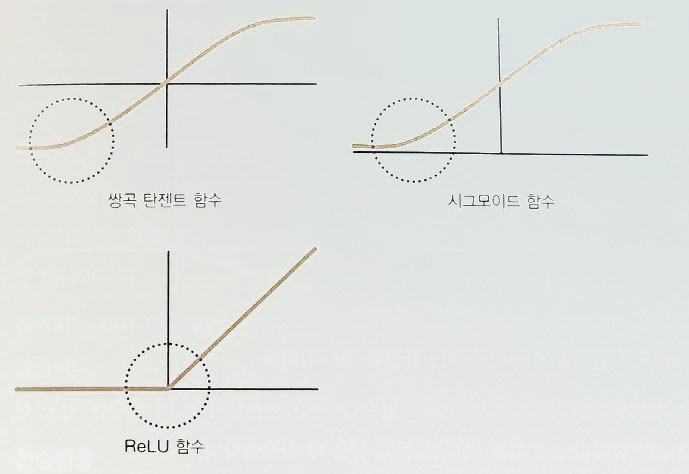

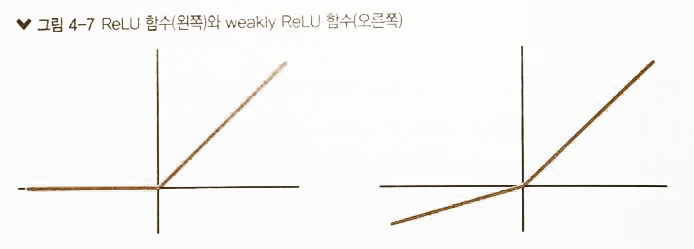
출력층 활성화 함수 ( Output layer activation function )
- softmax을 자주 사용합니다.
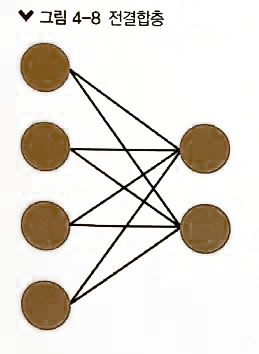
계층의 종류 ( Layer class )
- 전결합층
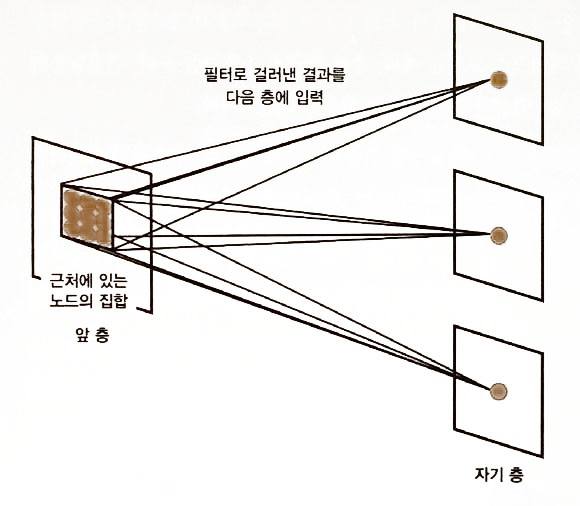
- 컨볼루션층 (convolution layer): 이미지에서 특징을 추출
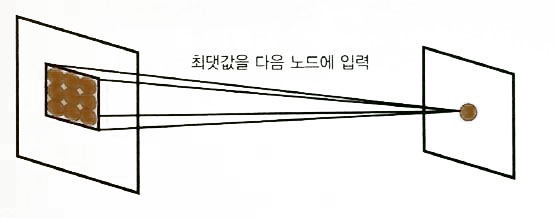
- 풀링층(pooling layer) : 국소적인 노드의 최대값을 취합 : 범위내 작은 변화는 같은 결과 값으로 표현.
Gradient Method

신경망을 정밀하게 학습
- Dropout : 2012년 Hinton교수가 제안.
- 임의의 노드 몇개를 생략하고 계산함. 또 다음 계산때에도 임의의 노드를 생략하고 계산.
- 입력층에는 20%, 은닉층에서는 50%
- 앙상블 학습과 비슷
- Drop connect : 연결가중치를 램덤하게 생략.
- Adaptive Dropout : 연결상황에 따라.
- AdaGrad
- AdaDelta
- Adam
오토인코더( Autoencoder )의 학습 방법
- 입력층과 출력증의 값이 같은 Neural Network
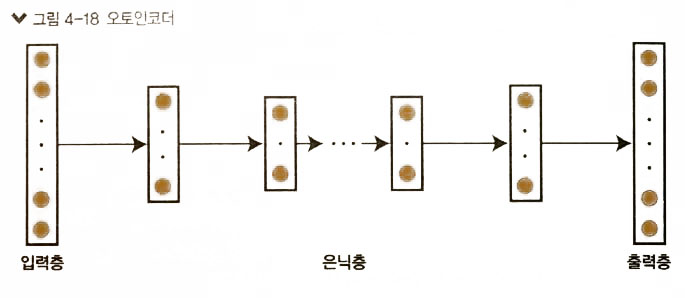
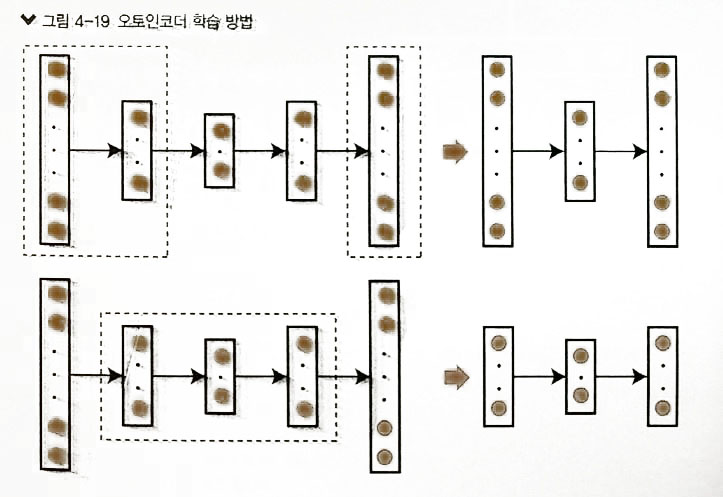
- 학습방법
- 입력층,1st 은닉층, 출력층으로 먼저 학습. –> 가중치 계산
- 1st 은닉층, 2nd 은닉층, 3th 은닉층 –> 학습
4 Caffe을 준비하다.
-
Caffe란 : 버클리대학교 BVLC(Berkerly Vision and Learning Centor )에서 개발한 Framework
-
Open Source Framework