Welcome to Jaehyek's Blog!
Here is my front-end learning path-
Deep Learning summary from http://hunkim.github.io/ml/ (2)
Canadian Institute for Advanced Research (CIFAR)
Google DeepMind’s Deep Q-learning playing Atari Breakout
Multinomial classification
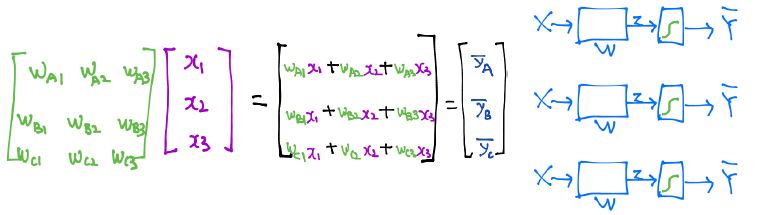
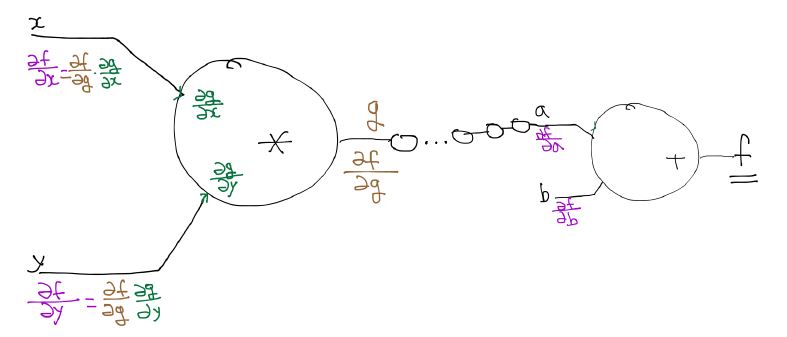
Back propagation
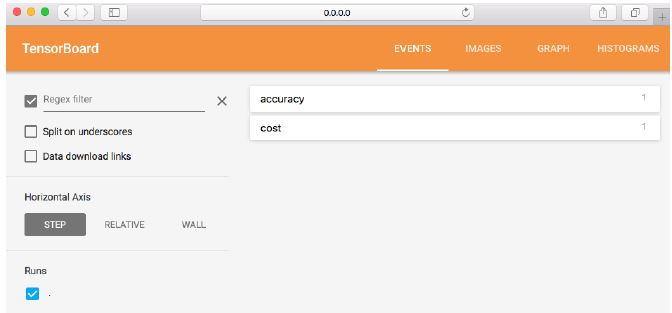
5 steps of using tensorboard
- From TF graph, decide which node you want to annotate
- with tf.name_scope(“test”) as scope:
- tf.histogram_summary(“weights”, W), tf.scalar_summary(“accuracy”, accuracy)
- Merge all summaries
- merged = tf.merge_all_summaries()
- Create writer
- writer = tf.train.SummaryWriter(“/tmp/mnist_logs”, sess.graph_def)
- Run summary merge and add_summary
- summary = sess.run(merged, …); writer.add_summary(summary);
- Launch Tensorboard
- tensorboard –logdir=/tmp/mnist_logs
- You can navigate to http://0.0.0.0:6006
import tensorflow as tf import numpy as np xy = np.loadtxt('07train.txt', unpack=True) x_data = np.transpose(xy[0:-1]) y_data = np.reshape(xy[-1], (4, 1)) print x_data print y_data X = tf.placeholder(tf.float32, name='x-input') Y = tf.placeholder(tf.float32, name='y-input') w1 = tf.Variable(tf.random_uniform([2, 5], -1.0, 1.0), name='weight1') w2 = tf.Variable(tf.random_uniform([5, 10], -1.0, 1.0), name='weight2') w3 = tf.Variable(tf.random_uniform([10, 10], -1.0, 1.0), name='weight3') w4 = tf.Variable(tf.random_uniform([10, 10], -1.0, 1.0), name='weight4') w5 = tf.Variable(tf.random_uniform([10, 10], -1.0, 1.0), name='weight5') w6 = tf.Variable(tf.random_uniform([10, 10], -1.0, 1.0), name='weight6') w7 = tf.Variable(tf.random_uniform([10, 10], -1.0, 1.0), name='weight7') w8 = tf.Variable(tf.random_uniform([10, 1], -1.0, 1.0), name='weight8') b1 = tf.Variable(tf.zeros([5]), name="Bias1") b3 = tf.Variable(tf.zeros([10]), name="Bias3") b2 = tf.Variable(tf.zeros([10]), name="Bias2") b4 = tf.Variable(tf.zeros([10]), name="Bias4") b5 = tf.Variable(tf.zeros([10]), name="Bias5") b6 = tf.Variable(tf.zeros([10]), name="Bias6") b7 = tf.Variable(tf.zeros([10]), name="Bias7") b8 = tf.Variable(tf.zeros([1]), name="Bias8") L2 = tf.nn.relu(tf.matmul(X, w1) + b1) L3 = tf.nn.relu(tf.matmul(L2, w2) + b2) L4 = tf.nn.relu(tf.matmul(L3, w3) + b3) L5 = tf.nn.relu(tf.matmul(L4, w4) + b4) L6 = tf.nn.relu(tf.matmul(L5, w5) + b5) L7 = tf.nn.relu(tf.matmul(L6, w6) + b6) L8 = tf.nn.relu(tf.matmul(L7, w7) + b7) hypothesis = tf.sigmoid(tf.matmul(L8, w8) + b8) with tf.name_scope('cost') as scope: cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1-Y) * tf.log(1 - hypothesis)) cost_summ = tf.summary.scalar("cost", cost) with tf.name_scope('train') as scope: a = tf.Variable(0.1) optimizer = tf.train.GradientDescentOptimizer(a) train = optimizer.minimize(cost) w1_hist = tf.summary.histogram("weights1", w1) w2_hist = tf.summary.histogram("weights2", w2) b1_hist = tf.summary.histogram("biases1", b1) b2_hist = tf.summary.histogram("biases2", b2) y_hist = tf.summary.histogram("y", Y) init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) merged = tf.summary.merge_all() writer = tf.summary.FileWriter("./logs/xor_logs", sess.graph) for step in xrange(20000): sess.run(train, feed_dict={X: x_data, Y: y_data}) if step % 200 == 0: summary = sess.run(merged, feed_dict={X: x_data, Y: y_data}) writer.add_summary(summary, step) print step, sess.run(cost, feed_dict={X: x_data, Y: y_data}), sess.run(w1), sess.run(w2) correct_prediction = tf.equal(tf.floor(hypothesis+0.5), Y) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print sess.run([hypothesis, tf.floor(hypothesis+0.5), correct_prediction], feed_dict={X: x_data, Y: y_data}) print "accuracy", accuracy.eval({X: x_data, Y: y_data})ReLU: Rectified Linear Unit
- L1 = tf.sigmoid(tf.matmul(X, W1) + b1)
-
L1 = tf.nn.relu(tf.matmul(X, W1) + b1)
- maxout = max(w1x + b1, w2x + b2 )
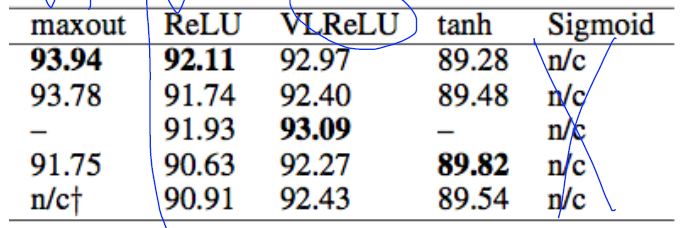
Activation functions on CIFAR-10
Need to set the initial weight values wisely
- Not all 0’s
- Challenging issue
- Hinton et al. (2006) “A Fast Learning Algorithm for Deep Belief Nets”
- Restricted Boatman Machine (RBM) : not used these day
- recreate input ( encoder/decoder )
- Deep Belief Net ( initialized by RBM )
Good news
- No need to use complicated RBM for weight initializations
- Simple methods are OK
- Xavier initialization
- He’s initialization
- Makes sure the weights are ‘just right’, not too small, not too big
- Using number of input (fan_in) and output (fan_out)
# Xavier initialization # Glorot et al.2010 W = np.random.randn(fan_in, fan_out)/np.sqrt(fan_in) # He et al.2015 W = np.random.randn(fan_in, fan_out)/np.sqrt(fan_in/2)- prettytensor implementation
def xavier_init(n_inputs, n_outputs, uniform=True): """Set the parameter initialization using the method described. This method is designed to keep the scale of the gradients roughly the same in all layers. Xavier Glorot and Yoshua Bengio (2010): Understanding the difficulty of training deep feedforward neural networks. International conference on artificial intelligence and statistics. Args: n_inputs: The number of input nodes into each output. n_outputs: The number of output nodes for each input. uniform: If true use a uniform distribution, otherwise use a normal. Returns: An initializer. """ if uniform: # 6 was used in the paper. init_range = math.sqrt(6.0 / (n_inputs + n_outputs)) return tf.random_uniform_initializer(-init_range, init_range) else: # 3 gives us approximately the same limits as above since this repicks # values greater than 2 standard deviations from the mean. stddev = math.sqrt(3.0 / (n_inputs + n_outputs)) return tf.truncated_normal_initializer(stddev=stddev)- Activation functions and initialization on CIFAR-10
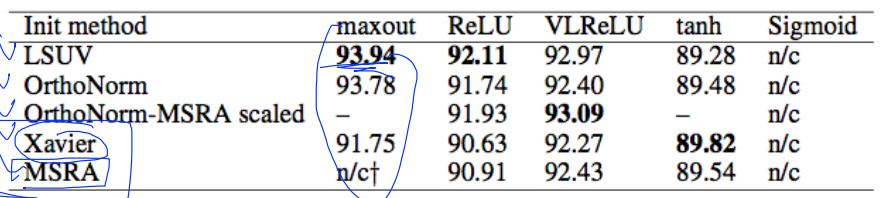
- Geoffrey Hinton’s summary of findings up to today
- Our labeled datasets were thousands of times too small.
- Our computers were millions of times too slow
- We initialized the weights in a stupid way
- We used the wrong type of non-linearity
Overfitting
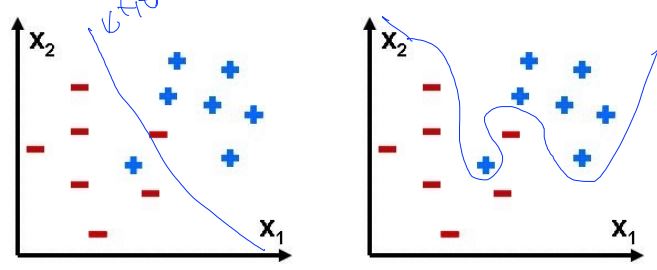
- Solutions for overfitting
- More training data
- Reduce the number of features
- Regularization
- Let’s not have too big numbers in the weight

- Let’s not have too big numbers in the weight
-
Dropout: A Simple Way to Prevent Neural Networks from Overfitting [Srivastava et al. 2014]
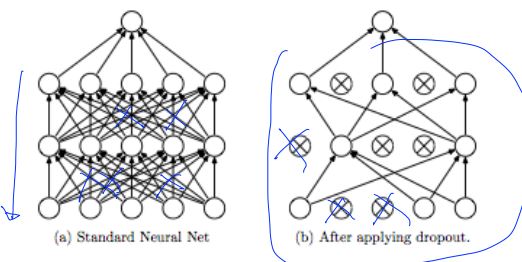
-
Regularization: Dropout “randomly set some neurons to zero in the forward pass”
- dropout TensorFlow implementation
dropout_rate = tf.placeholder("float") _L1 = tf.nn.relu(tf.add(tf.matmul(X, W1), B1)) L1 = tf.nn.dropout(_L1, dropout_rate)- TRAIN:
sess.run(optimizer, feed_dict={X: batch_xs, Y: batch_ys, dropout_rate: 0.7})
- EVALUATION:
print "Accuracy:", accuracy.eval({X: mnist.test.images, Y:mnist.test.labels, dropout_rate: 1})
What is the ensemble ?
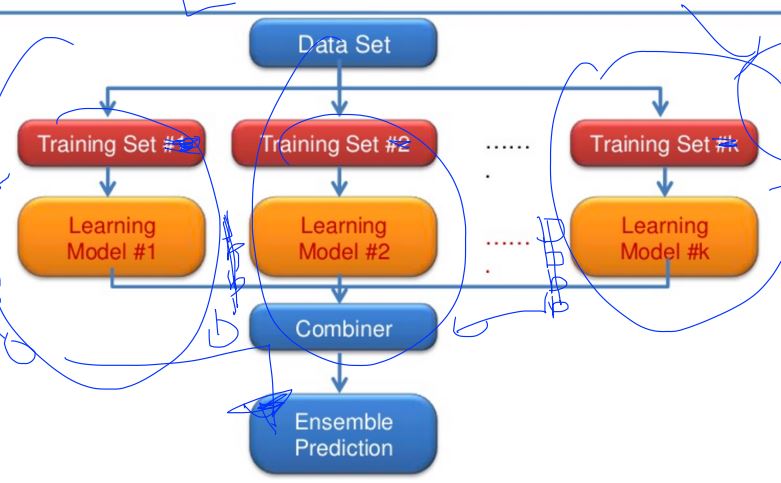
- From TF graph, decide which node you want to annotate
-
Deep Learning summary from http://hunkim.github.io/ml/ (1)
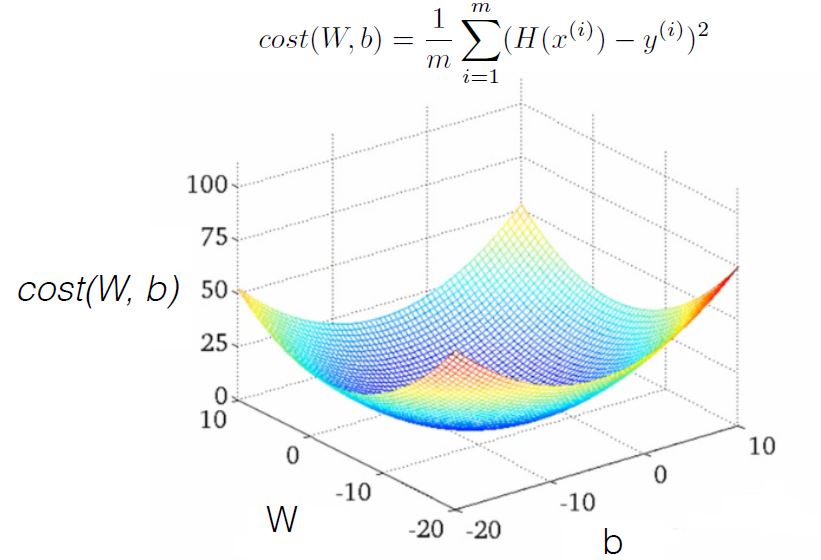
Simplified Hypothesis and Cost
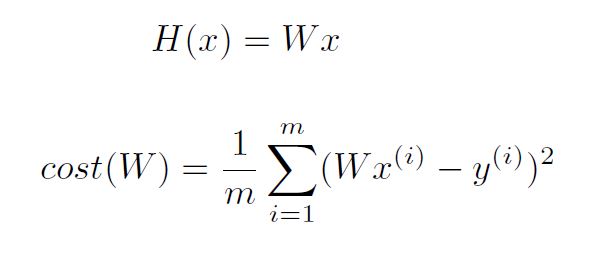
Gradient descent algorithm
- Minimize cost function
- Gradient descent is used many minimization problems
- For a given cost function, cost (W, b), it will find W, b to minimize cost
- It can be applied to more general function: cost (w1, w2, …)
How to work
- Formal definition
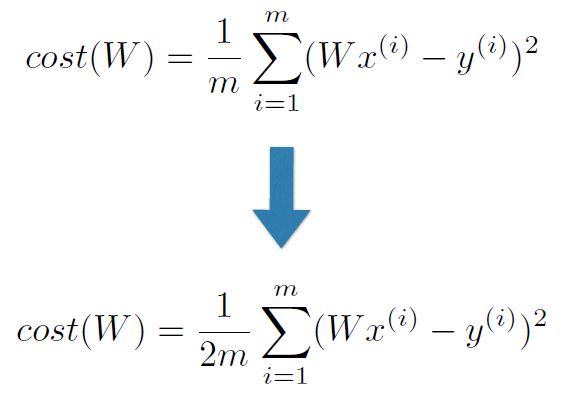
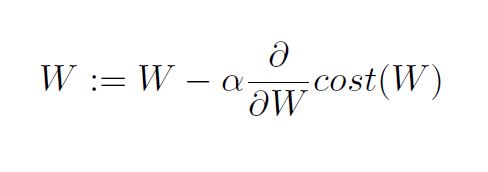
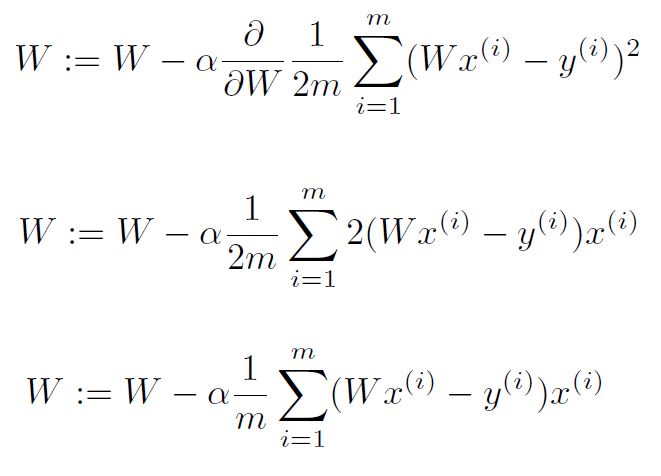
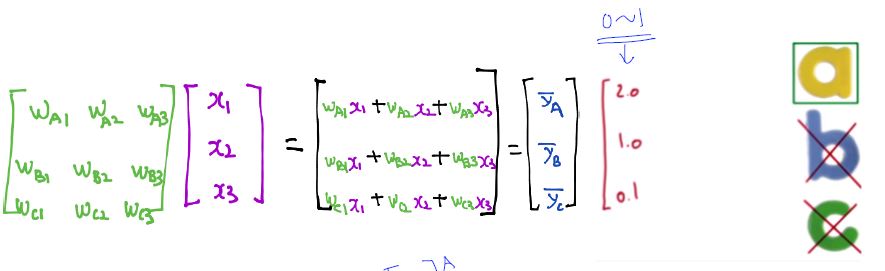
Hypothesis with Matrix
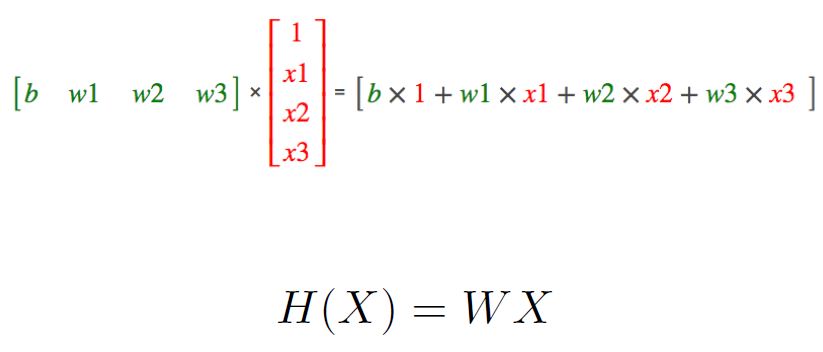
Logistic (regression) classification
Logistic Hypothesis
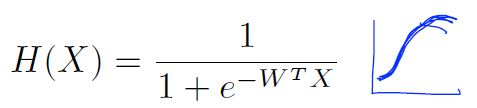
New cost function for logistic
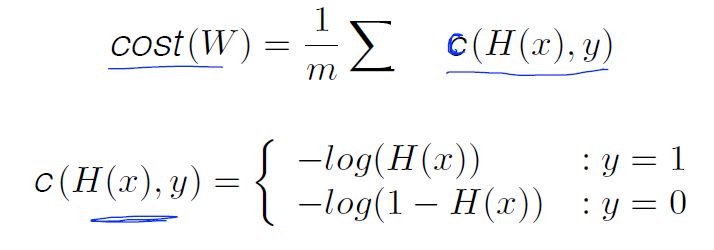
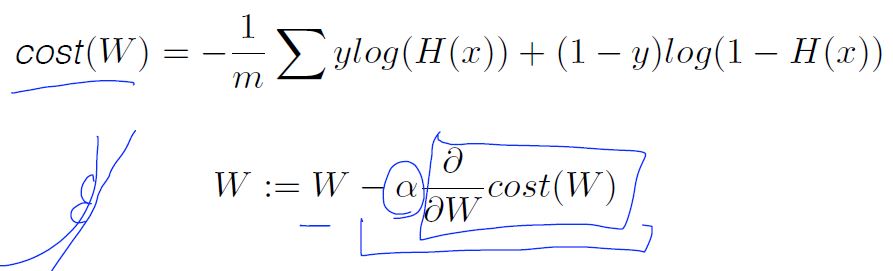
sample code
h = tf.matmul(W, X) hypothesis = tf.div(1., 1. + tf.exp(-h)) cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) * tf.log(1 - hypothesis)) a = tf.Variable(0.1) # learning rate, alpha optimizer = tf.train.GradientDescentOptimizer(a) train = optimizer.minimize(cost) # goal is minimize costMultinomial classification and Where is sigmoid?
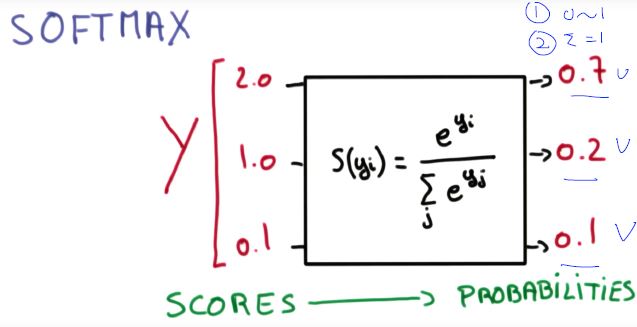
SOFTMAX
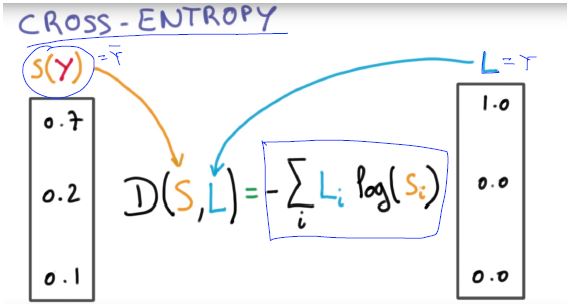
Cross-entropy cost function

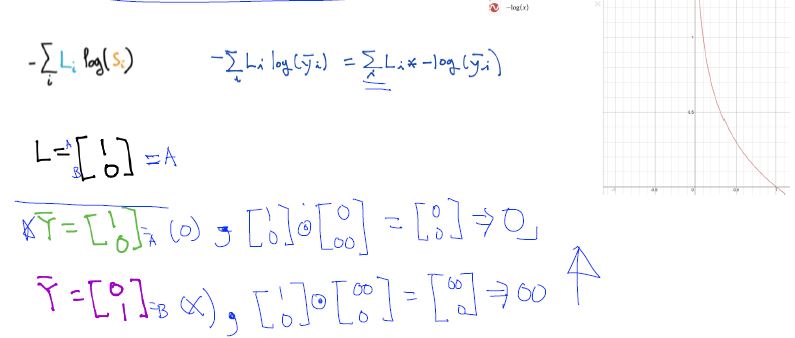
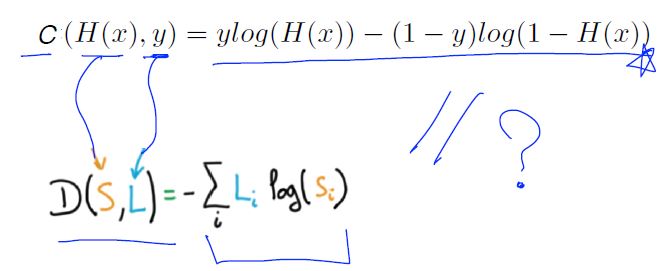
Data (X) preprocessing for gradient descent
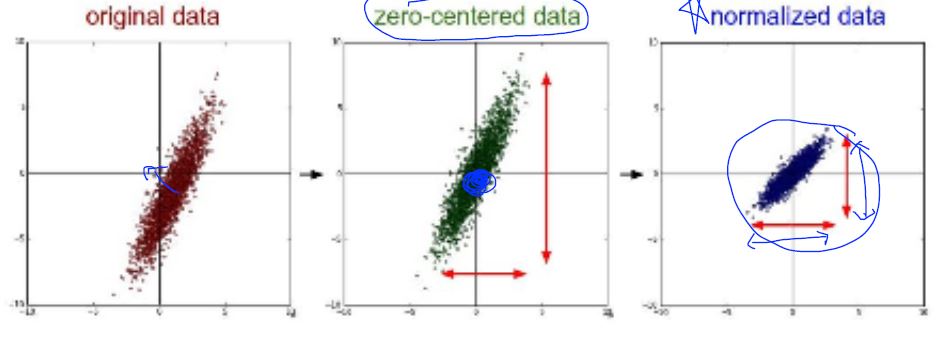
standardization
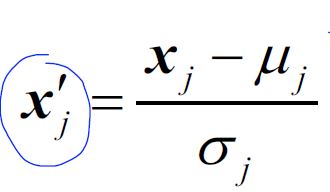
- X_std[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
Training, validation and test sets
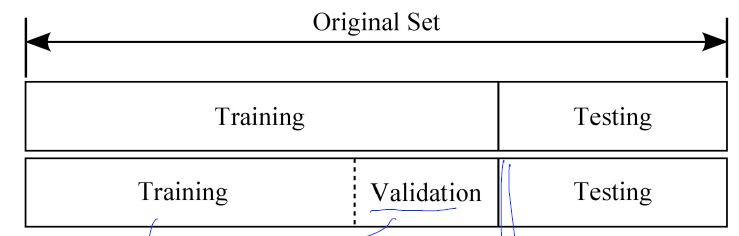
MINIST Dataset

- train-images-idx3-ubyte.gz : training set images (9912422 bytes)
-
train-labels-idx1-ubyte.gz : training set lables (18881 bytes)
- t10k-images-idx3-ubyte.gz : test set images (1648877 bytes)
-
t10k-labels-idx1-ubyte.gz : test set lables ( 4542 bytes)
- http://yann.lecun.com/exdb/mnist/
-
Summary of CNN base cs231n.github.io
CNN Base 인 cs231n을 정리하기
-
BOOK-TCP/IP 쉽게 더 쉽게-03
보안 프로토콜 적용하기
- HTTPS : HTTP + SSL/TLS을 적용한 것
- VPN : 통신 거점간의 통신을 통째로 암호화하는 방식하므로 app별로 암호화하지 않아도 된다.
공유키 : 하나의 키로 암호화/복호화가 가능한 방법
- 키를 공유할 모든 사람에게 공유해야 하므로 부담이 되는 방법
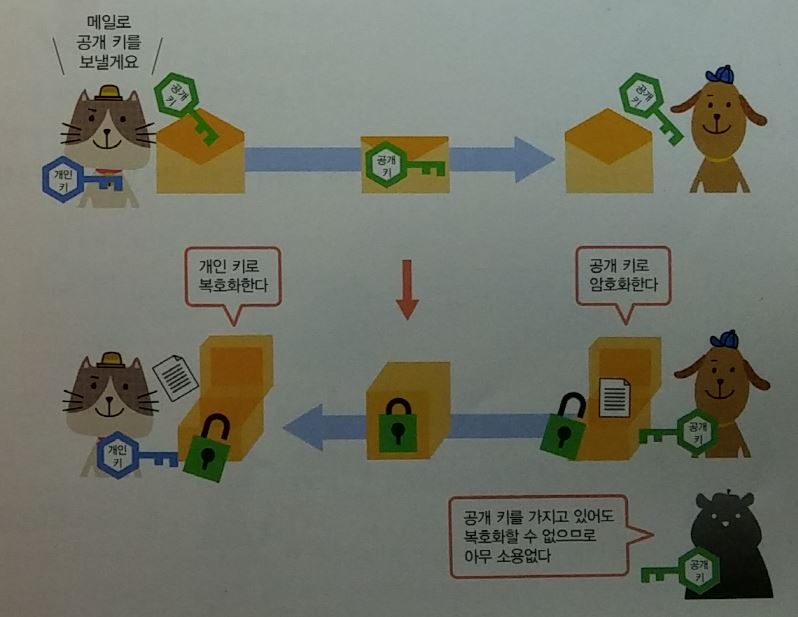
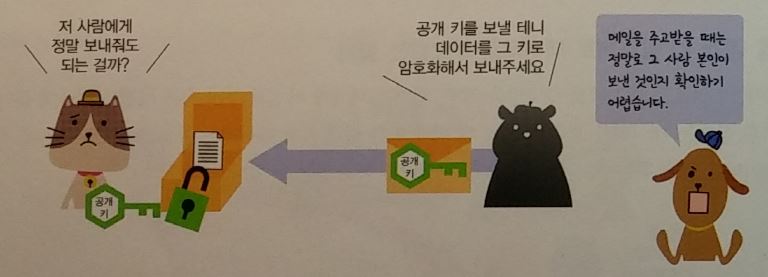
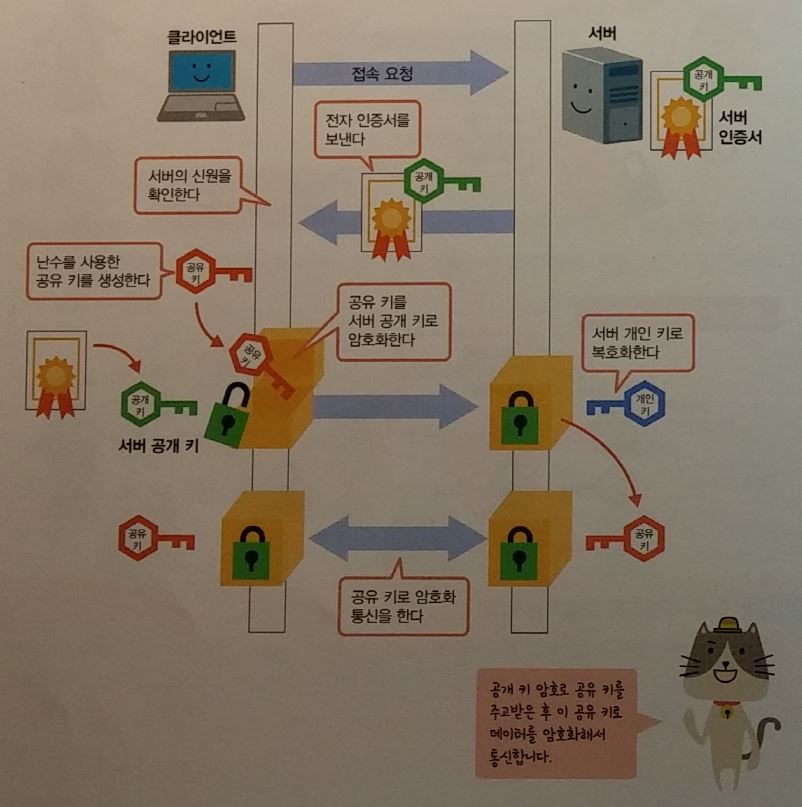
공개키 : 암호화키와 복호화키를 세트로 관리
- 개인키(비밀키) : 자신이 가지는 키
- 공개키 : 상대방에게 전달하는 키.
- 공개키와 개인키의 사용절차
전자인증서 : 사용자가 본인이라는 것을 증명
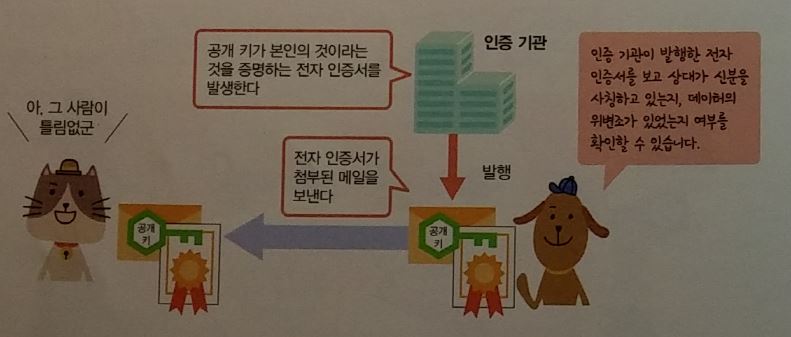
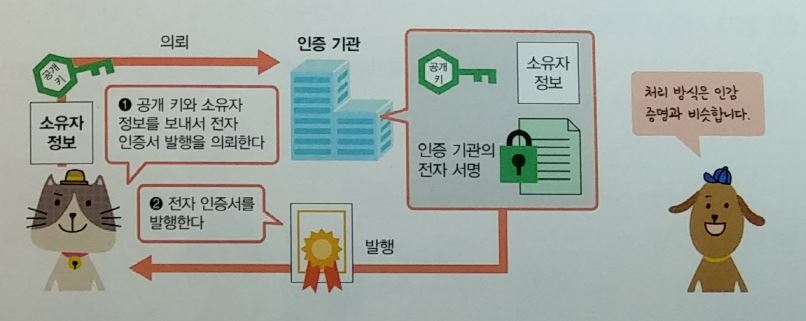
- PKI ( Public Key Infrastructure )
- CA ( Certification Authority ) : 한국정보인증, 코스콤, 한국전자인증, 한국무역정보통신, 금융결재원
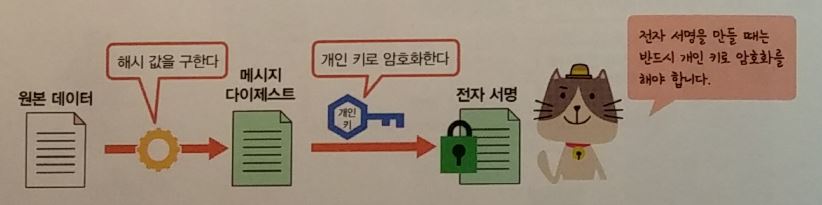
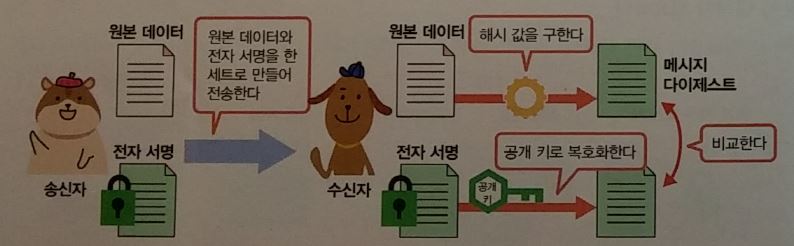
전자서명 : 데이터가 위변조 되지 않았다는 것을 증명
- 반드시 개인키로 암호화 한다.
- 개인키로 암호화한 데이터는 공개키로 복호화할 수 있다
이메일을 안전하게 전달 : S/MIME
- secure /Multipurpose Internet Mail Extenstion
-
이메일을 암복호화 할때는 공개키와 공유키를 조합 사용한다.
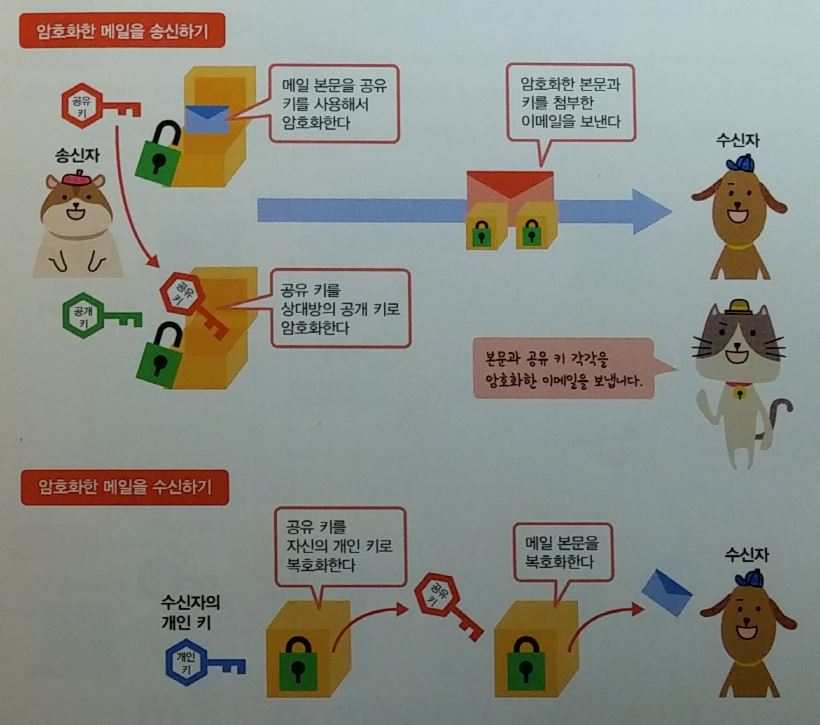
- 공유키 방식을 조합하는 이유 :
- 이메일 본문을 공개키 방식으로 암복호화하는 것보다 공유키 방식으로 암복호화하는 것이 연산처리에서 부담이 적다
SSL / TLS
-
SSL ( Secure Sockets Layer), TLS(Transport Layer Secure)
-
HTTPS : SSL/TLS을 사용한다.
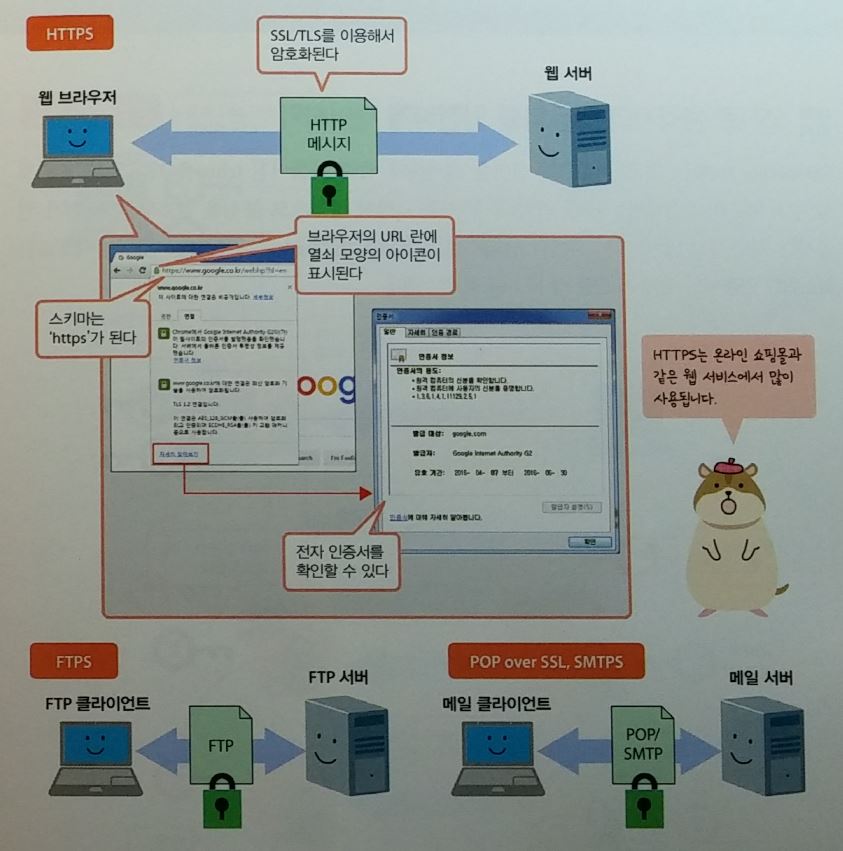
- SSL은 넷스케이프 커뮤니케이션즈가 개발하였고, IETF(Internet Engineering Task Force)는 이것을 TLS 로 퓨준화 후에 기존의 SSL을 대체하였다.
- TSL 대신 SSL이라고 부르는 경우가 많다.
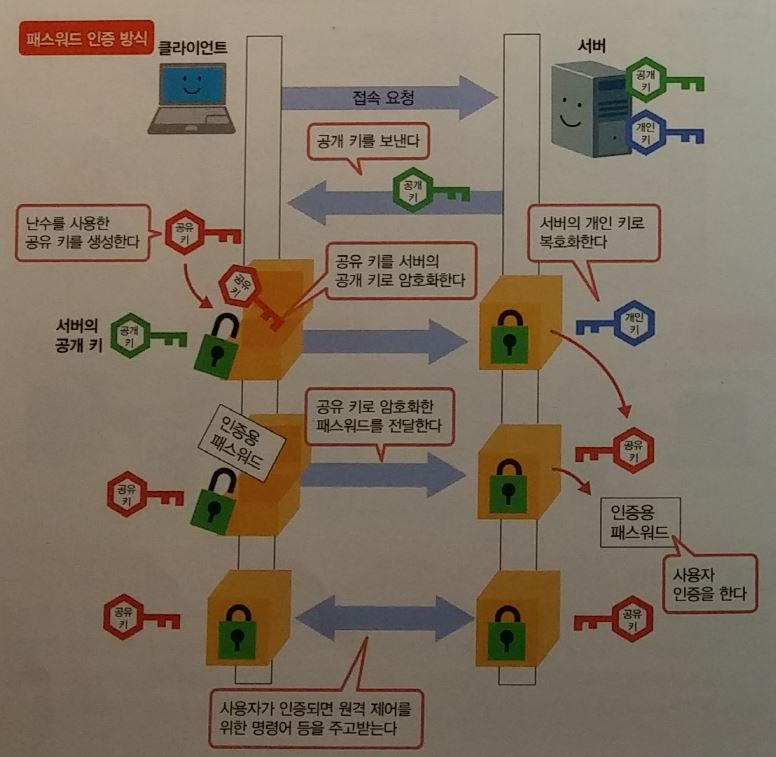
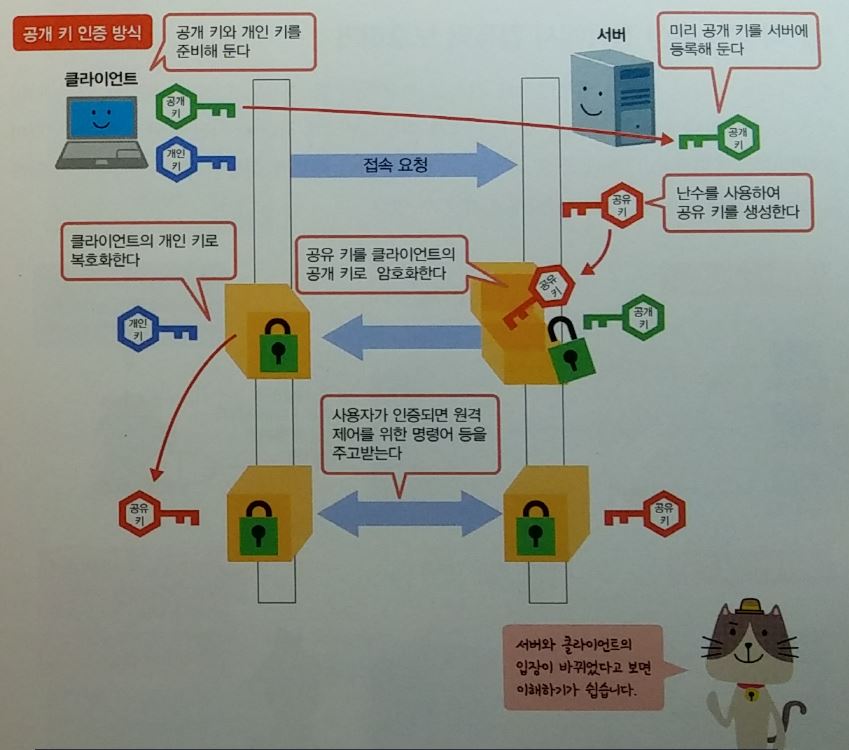
SSH ( Secure Shell )
- 원격지의 컴퓨터를 제어하기 위해
- 공개키와 공유키를 조합하여 사용.
- 전자인증서를 사용하지 않는다.
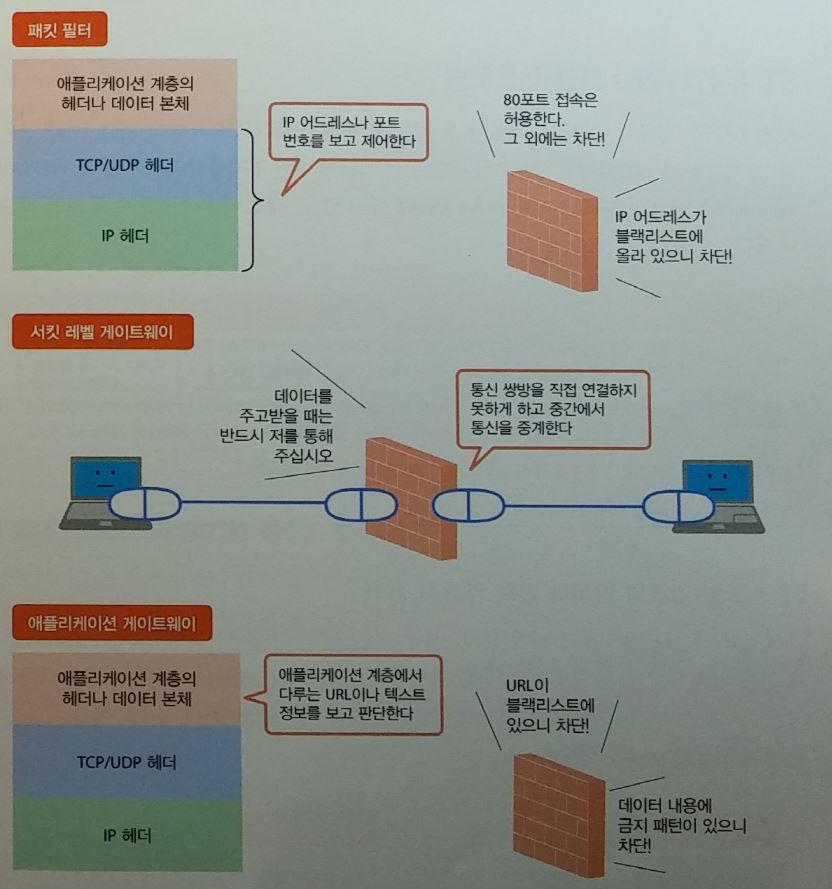
방화벽
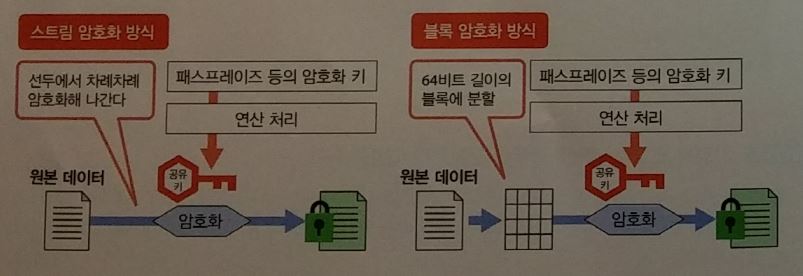
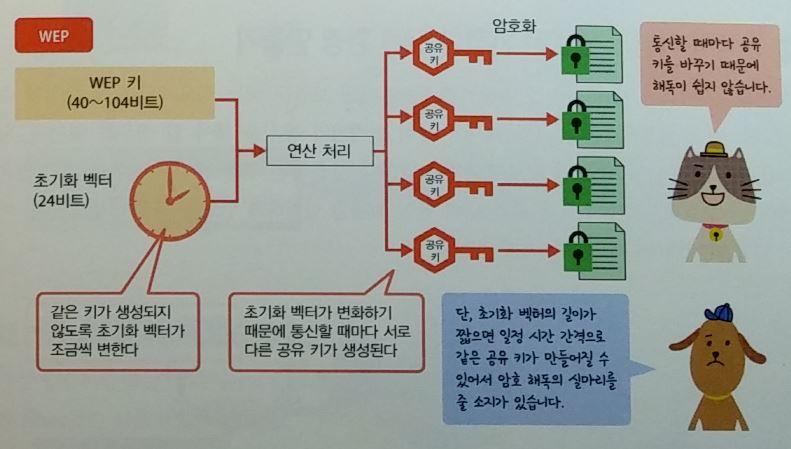
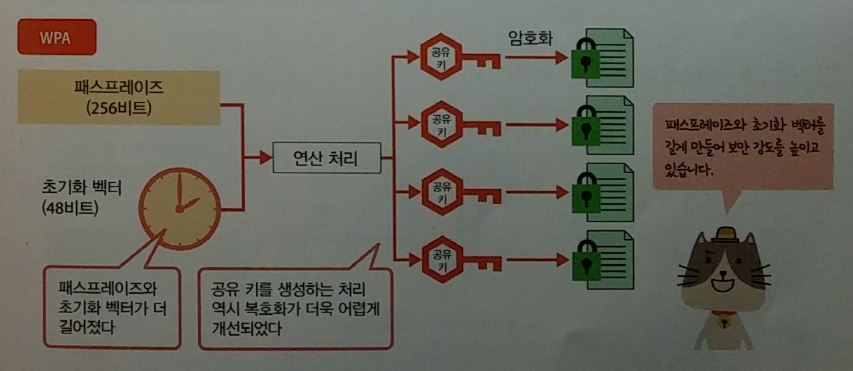
무선랜 보안
-
WEP(Wired Equipment Privacy), WPA(Wi-fi Protected Access)

- 암복호화 하기 위해 공유키를 사용한다.
- WPA2에서는 블록 암호화 방식을 사용한다
패스프레이즈
- 키 = 패스프레이즈(사용자가 지정한 문자열) + 초기화벡터(조금씩 변화는 값)
- 암호화는 쉽고, 복호화는 어렵다
VPN
-
Virtual Private Network
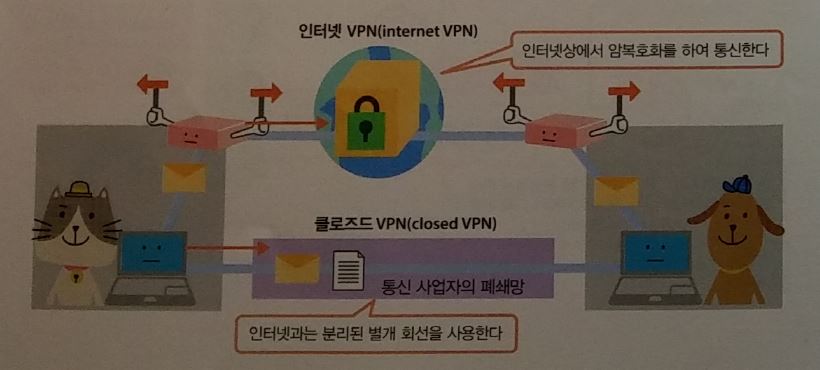
- IPSec(Security Architecture for Internet Protocol)
- PPTP(Point to Point Tunneling Protocol)
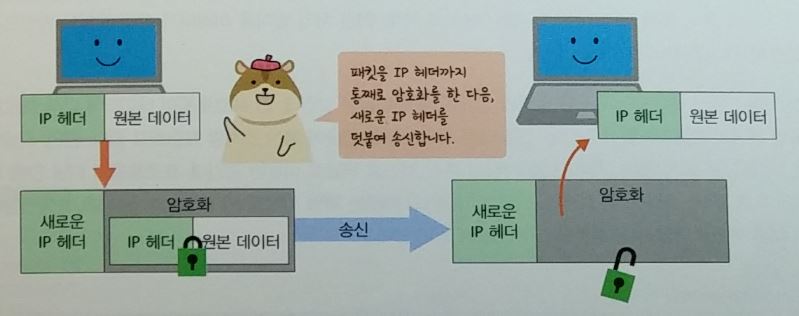
-
BOOK-TCP/IP 쉽게 더 쉽게-02
네트워크 인터페이스
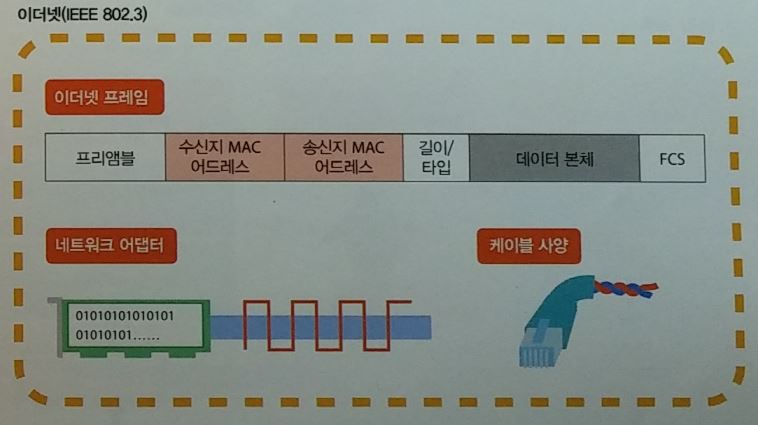
PPP : 전화회선을 사용해서 원격지와 접속 이더넷: UTP 케이블을 사용 ARP : IP address 를 이용하여 목적지의 MAC address 찾기
MAC address
- Media Access Control

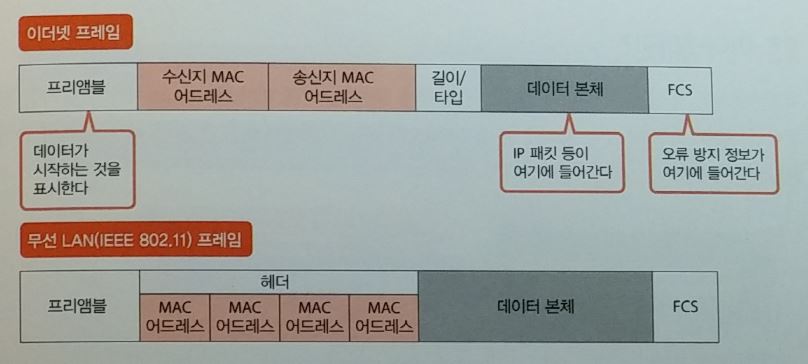
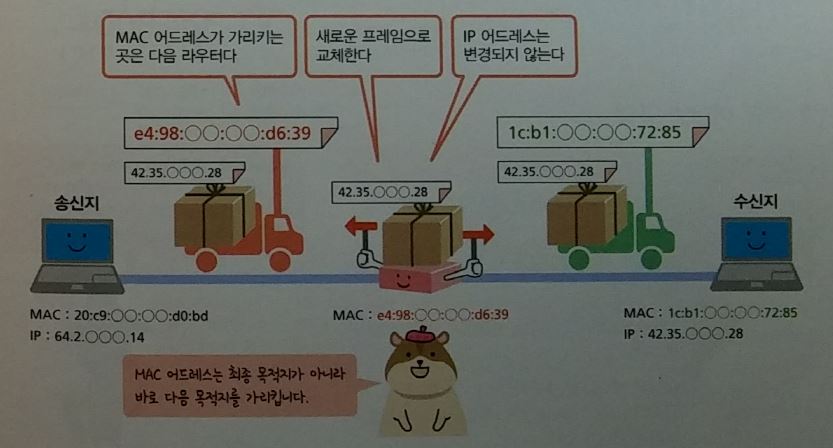
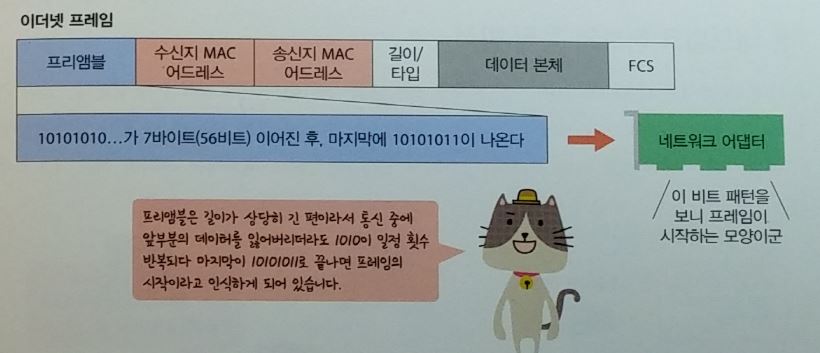
이더넷
- 유선 LAN 규격

프리엠블 (preamble )
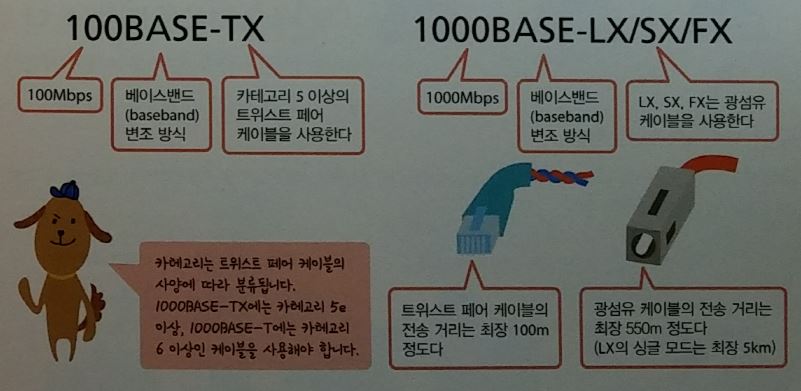
케이블 종류
L2 스워치 : 접속된 상대만 인식
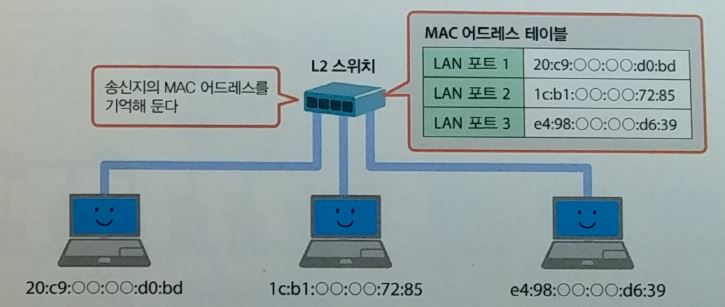
- broadcast 도메인 : broadcast address가 data가 도달할 수 있는 범위
L3 스워치 : 인터넷계층까지 기능수행
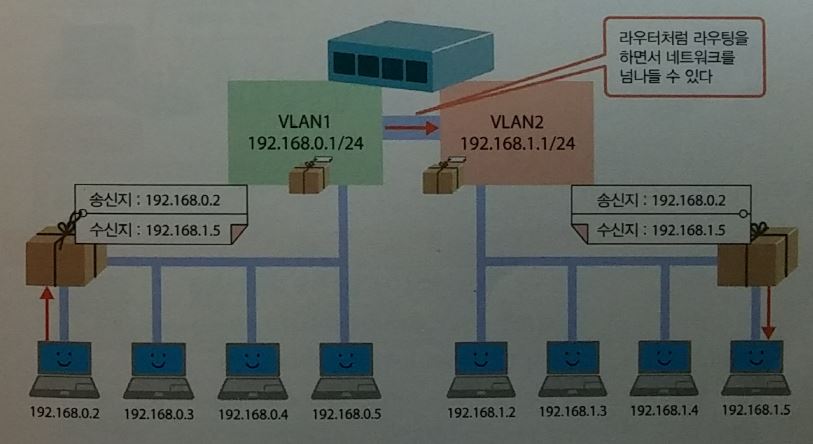
- VLAN : 가상의 네트워크를 분할해서 지역을 나눈다. 통신효율을 높인다.
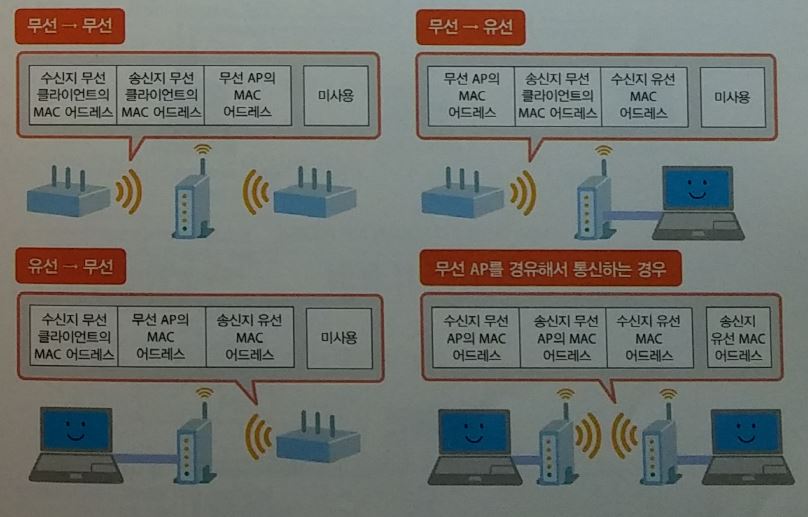
무선통신 규격

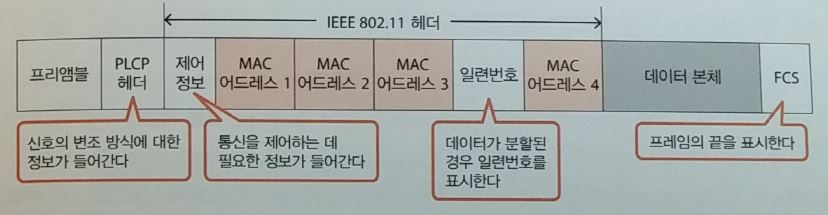
- 무선LAN Frame 구조
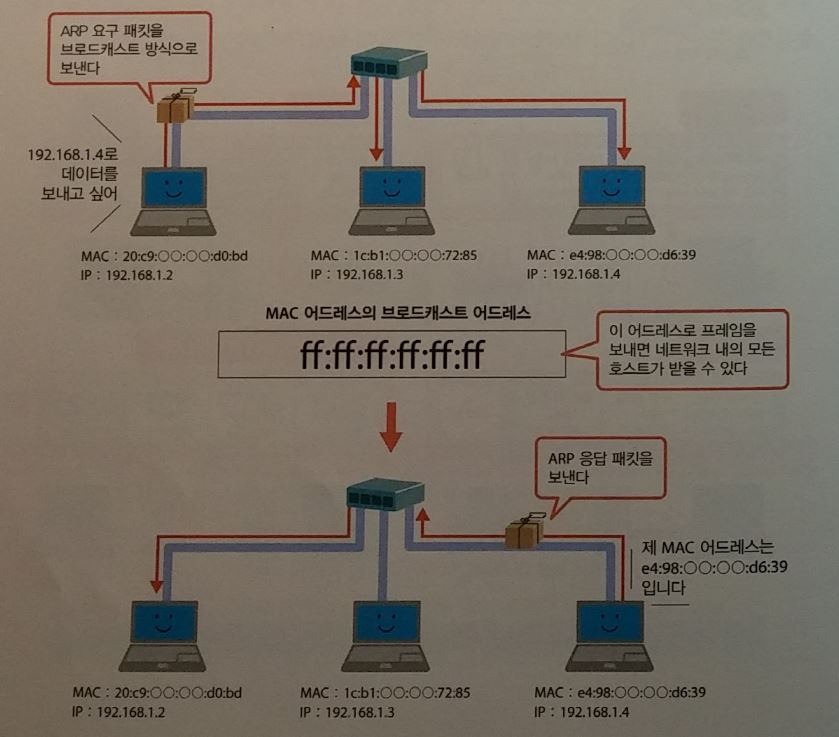
ARP ( Address Resolustion Protocol )
- 송신측은 수신 IP을 요청 패킷에 설정하고 브로드캐스트한다.
-
명령어로 “ARP -a “ : 캐시에 있는 것도 표시할 때.
- ARP Header
-
헤더 내의 오퍼래이션 코드가 1:요청, 2:응답
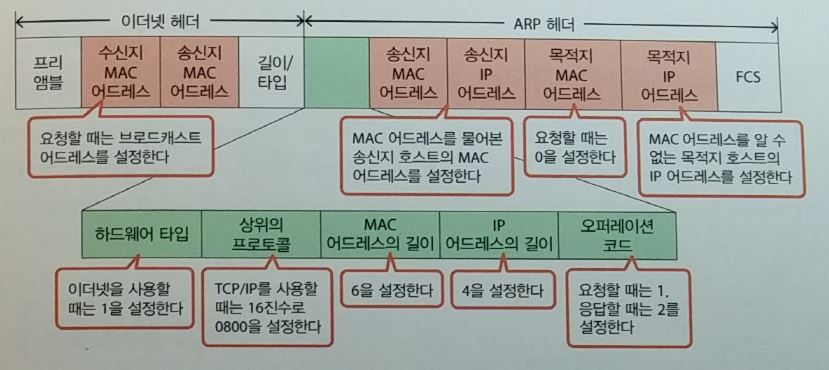
- 프락시 ARP : 호스트 대신, router가 ARP 기능을 하는 것.
FTTx : 광섬유 케이블을 사용
xDSL : 금속 케이블을 사용
PPP : 컴퓨터와 1대1 로 통신
-
eMMC Protocol Analyzer
eMMC Protocol Analyzer Setup

[SGDK330B information]
SGDK330B was newly lined up to analyzer (June 2015)
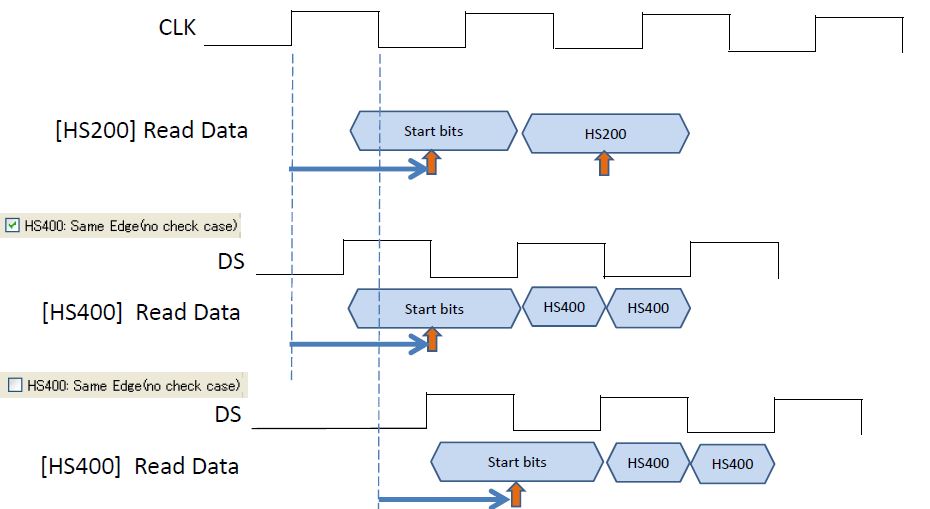
SGDK330B Main POD has 1GB memory on board, so it has following functions- SGDK330B can save all of protocol information of HS400 mode.
- On the other hand, SGDK330A cannot save all of protocol information of HS400 mode.
- SGDK330A can save only 256Byte (half of one sector) information of HS400 mode.
- Maximum LOG size of SGDK330B is 1GB
Architecture of SGDK330B is the same as SGDK330A.
All of Mini POD can be used for both SGDK330A and SGDK330B.
Differences between SGDK330A and SGDK330B are the items which are related to 1GB on board.Mechanism
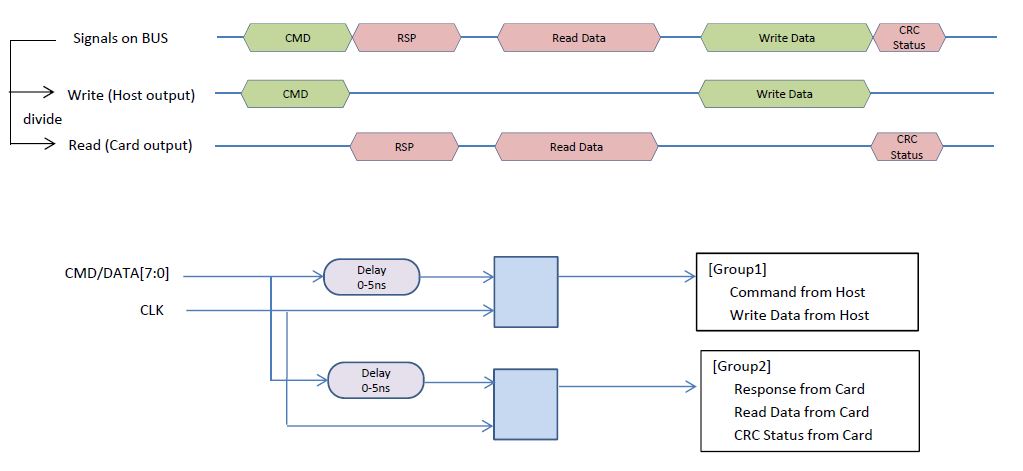
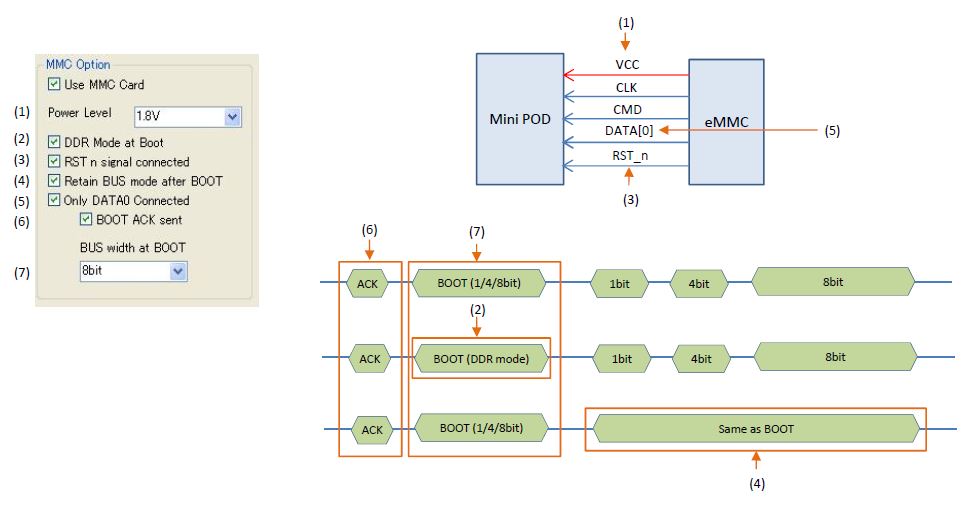
All of data (DATA[7:0]) are connected case
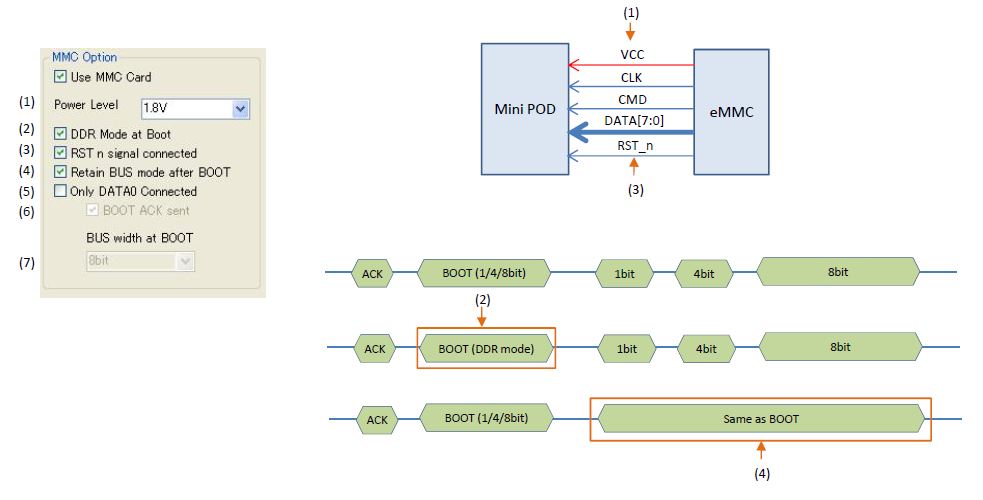
Only DATA[0] is connected case
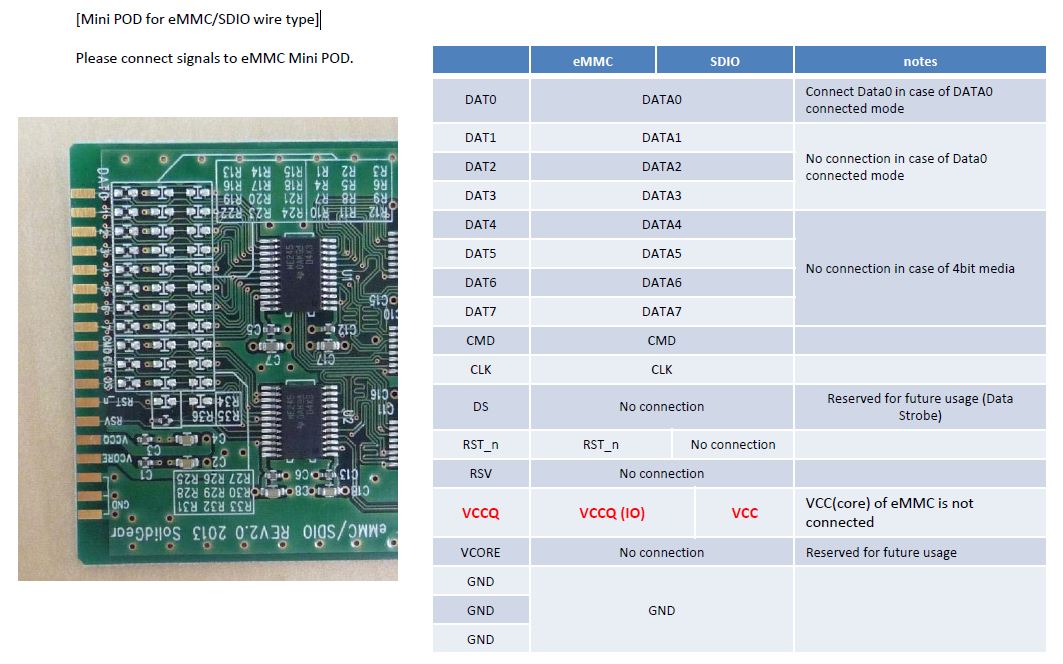
Mini POD for eMMC/SDIO wire type]
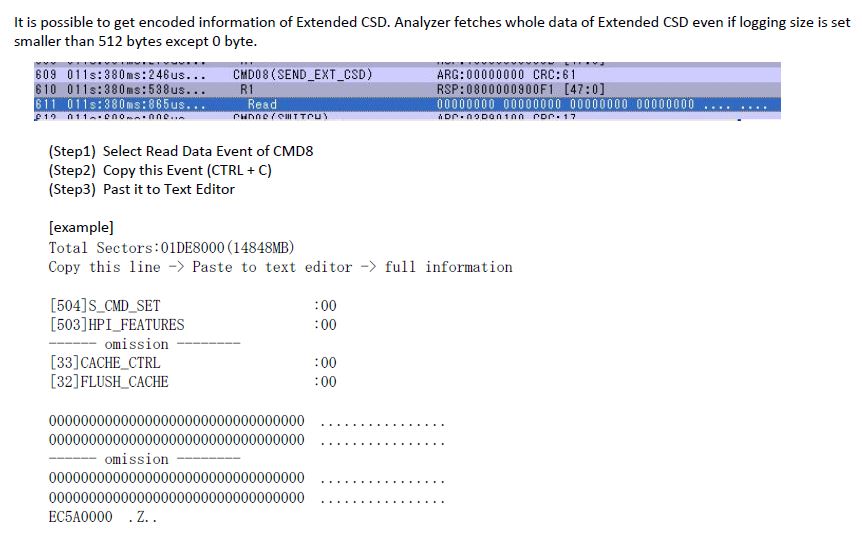
CMD8 (SEND_EXT_CSD)]
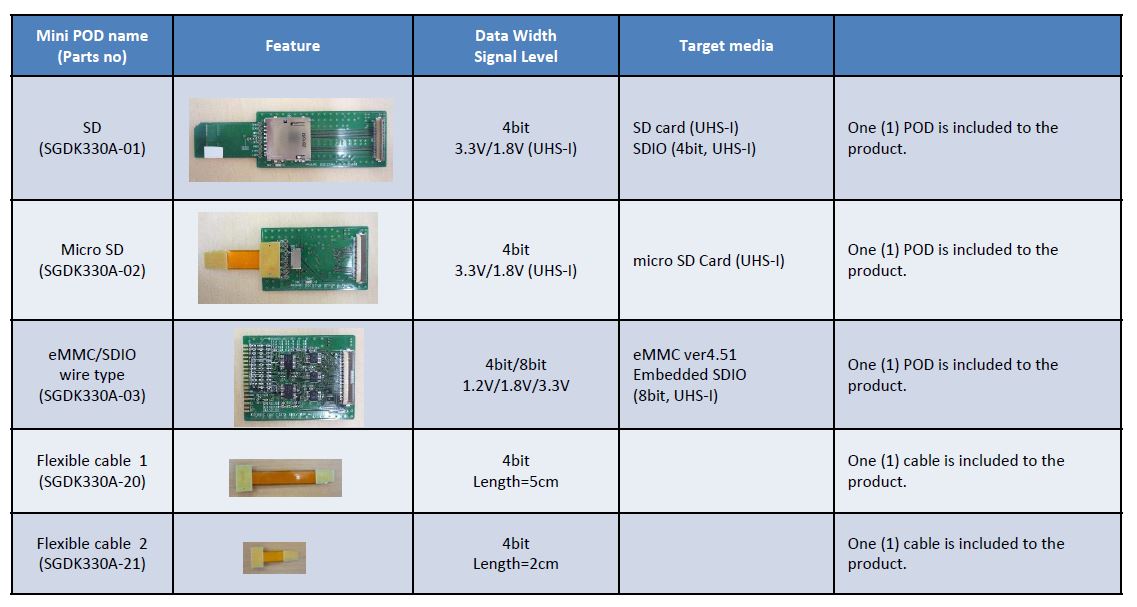
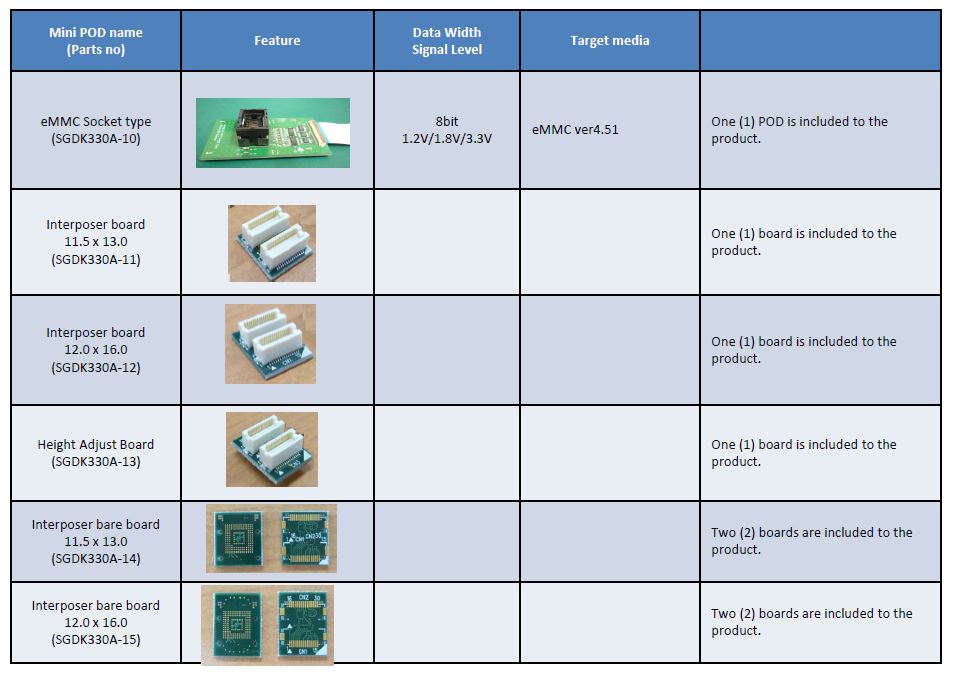
Mini POD

- Install Tensorflow and OpenCV on Raspberry PI 3
- Install Tensorflow on Windows
- Tensorflow 0.x => 1.0 Migration Guide
- eMMC UFS Issues 17
- Deep Learning summary from http://hunkim.github.io/ml/ (4)
- Deep Learning summary from http://hunkim.github.io/ml/ (3)
- Deep Learning summary from http://hunkim.github.io/ml/ (2)
- Deep Learning summary from http://hunkim.github.io/ml/ (1)
- Summary of CNN base cs231n.github.io
- BOOK-TCP/IP 쉽게 더 쉽게-03