refer to http://laonple.blog.me/220522735677
What is the overfitting ?
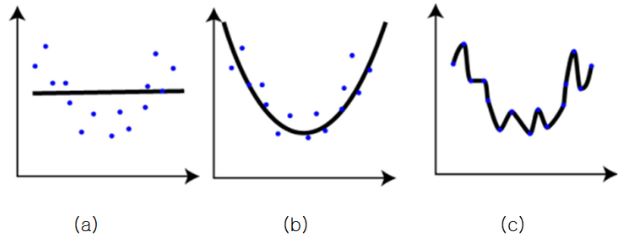 Let’s look over the above picture. Given some blue points, guess a curve to represent the points
Let’s look over the above picture. Given some blue points, guess a curve to represent the points
- picture(a) : seems like that a simple line has a error to represent those.
- picture(c) : is inferenced that the lime represent the whole points perfectly. but Although it got the optimization results, if given a point, that would produce the wrong result. we call this overfitting !!!.
- picture(b) : the line represents the whole points although it has a little error. also if given a point , it would still represent the whole thing well.
How to resolve the overfitting ?
The perfect solution to avoid the overfitting is to collect a lot of data. But it would make a lot of time or cost. sometime it would be difficult or impossible to gathering more data.
Additinally if given a lot of training data, increasing training time would also become a issue.
When statistical inferencing or running the machime learning normally, the cost function or error function goes to a lower error. But just simple lower error can go to bad result.
Solution 1 ) the below picture showes that the regularization makes good results.
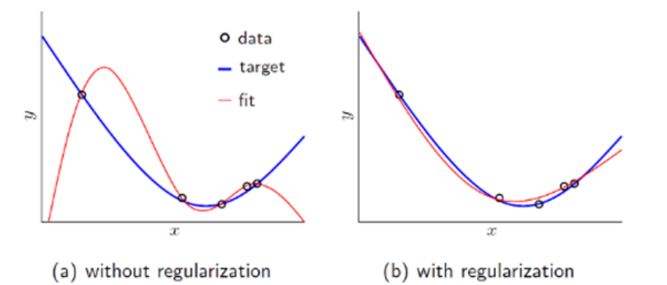
* the mathematical presentation of Regularization .
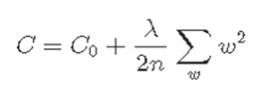
C0 = Cost function n = data count λ = traning rate w = weights
the learning direction is to go the lower cost , and also the w value got to go to lower
By Differentiating with w , finally a new w get to become like below .
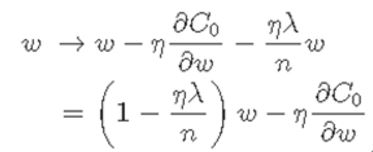
At the above, (1 – ηλ/n)w will make the w value lower as the n increases.
This is called “weight decay”.
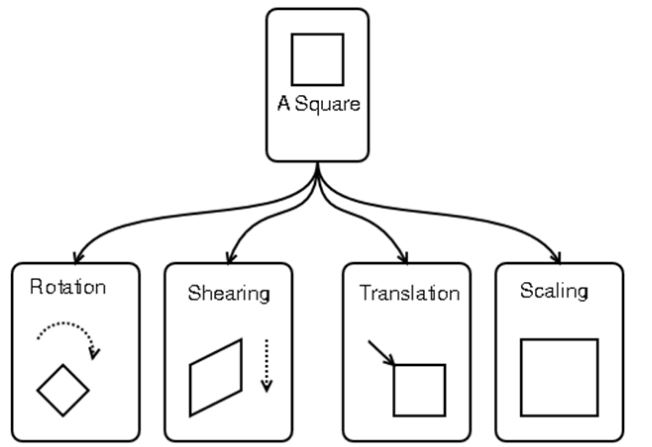
Solution 2 ) Intelligent training data generation using Affine Transform
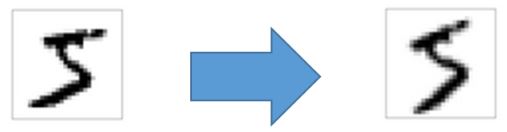
The above figure shows data obtained by rotating the left-handed data counter-clockwise by 15 degrees.
After this affine transform,Various data can be obtained.
Affine transform has four operations as shown below, Combining these can provide a lot of training data
Solution 3 ) Intelligent training data generation using Elastic Distortion
Create a displacement vector in various directions as shown below.
This allows us to create more complex forms of training data, It will be obvious that this will be a training data set useful for handwriting recognition

In the case of speech recognition, similar training data can be generated.
For example, after recording with no noise, Through synthesis with various background noise,
Various training data sets can be created.
Solution 4) Dropout
** Advantage and Disadvantage of increasing number of Hiddern Layers.**
In general, as the number of hidden layers increases in neural network,
In other words, a deep neural network can improve the ability to solve more problems
However, as the net size increases, the possibility of overfitting increases,
and there is a problem that the learning time for the neural network is lengthened,
the amount of learning data should be increased too to get a proper results .
Dropout overview
As the network size increase like this, the method to avoid the overfitting is dropout,
it has not been more than 10 years since the paper was published.
Dropout, when learning about figure (a) below,
Instead of learning about all the layers in the network
As shown in (b), some neurons in the input layer or hidden layer in the network are dropped out
The learning is performed through the reduced neural network.
If you finish learning the omitted network during a certain mini-batch period,
Repeated learning is performed while dropping out other neurons randomly
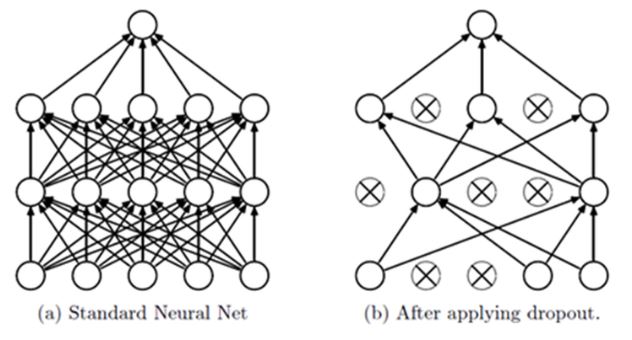
Dropout effect
① Voting
The first reason for dropout is because of the voting effect.
If you are learning using a reduced network during a certain mini-batch period,
The network is overfitting itself,
If you learn about other networks during other mini-batch intervals,
The network is again overfitting to some extent.
When this process is repeated randomly,
Since the average effect by voting can be obtained,
As a result, you can get a similar effect to regularization
② Effect to avoid Co-adaptation
Another reason is the avoidance of co-adaptation.
As we have seen in Regularization,
When the bias or weight of a particular neuron has a large value
As its influence increases, the learning rate of other neurons slows
There are cases where learning does not work properly.
But when you do the dropout,
As a result, the weight or bias of any neuron is not affected by a particular neuron
As a result, neurons can avoid co-adaptation.
It is possible to construct a more robust network that is not affected by specific learning data or data.
This means that life forms that exist on Earth for a long time
Binding genes through positive reproduction, not gene replication
Just as stronger genes survive the selection of nature